|
Visual Servoing Platform
version 3.6.1 under development (2025-02-27)
|
|
Visual Servoing Platform
version 3.6.1 under development (2025-02-27)
|
This tutorial will show how to use Blender, a free and open source 3D creation suite, to create a simple textured object like a tee box, generate color and depth images from a virtual RGB-D camera, retrieve color and depth camera intrinsics and get ground truth color camera poses while the RGB-D camera is animated.
Once generated by Blender, data could be used by the model-based tracker and results could be compared with ground truth.
This tutorial was tested Ubuntu and macOS with the following versions:
| OS | Blender |
|---|---|
| Ubuntu 22.04 | Blender 3.6.4 |
| macOS Ventura 13.6 | Blender 3.4.1 |
Note that all the material (source code, input video, CAD model or XML settings files) described in this tutorial is part of ViSP source code (in tracking/model-based/generic-rgbd-blender folder) and could be found in https://github.com/lagadic/visp/tree/master/tracking/model-based/generic-rgbd-blender.
Remember that for each object considered by the model-based tracker, you need a Tracker CAD model (object_name.cao or object_name.wrl) and a file for Tracker initialization by mouse click (object_name.init).
In this tutorial we will consider a tea box. The CAD model file (teabox.cao) and the init file (teabox.init) are provided in model/teabox folder:
Instead of creating an object with any dimensions, to simplify this tutorial, in Blender we'll create a tea box whose dimensions, object frame, and 3D point coordinates correspond to those in the teabox.cao and teabox.init.
The content of the teabox.cao file is the following:
The corresponding CAD model is the following:
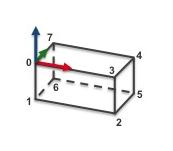
Analysing teabox.cao we can see that the box dimensions are the following (see teabox.cao example):
We will also consider a RGB-D camera where the left camera is a classical color camera and the right camera a depth camera. The distance between left and right cameras is 10 cm. Both cameras are grabbing 640 x 480 images.
| Camera | Setting | Values |
|---|---|---|
| Color | Image resolution | 640 x 480 |
| Focal lenght | 35 mm | |
| Sensor size | 32 mm x 24 mm | |
| Depth | Image resolution | 640 x 480 |
| Focal lenght | 30 mm | |
| Sensor size | 32 mm x 24 mm |
![\[ {\bf K} = \begin{bmatrix} p_x & 0 & u_0 \\ 0 & p_y & v_0 \\ 0 & 0 & 1 \end{bmatrix} \]](form_1555.png)
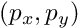 corresponds to the pixel size
corresponds to the pixel size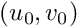 to the principal point location.
to the principal point location.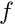 , the camera sensor size and the image resolution are the following:
, the camera sensor size and the image resolution are the following:
![\[ p_x = \frac{f \times \text{image width}}{\text{sensor width}} \]](form_1556.png)
![\[ p_y = \frac{f \times \text{image height}}{\text{sensor height}} \]](form_1557.png)
In this section, we will create the corresponding tea box, RGB-D camera and define an initial and final RGB-D camera pose used to animate the scene.
Here we will show how to create with Blender a box with the following dimensions:
Open Blender and do the following to transform the cube in a box with the expected dimensions:
"Object Mode" (1) select the "Cube" the right panel (2). Edges should appear in orange"Transform" panel (3) 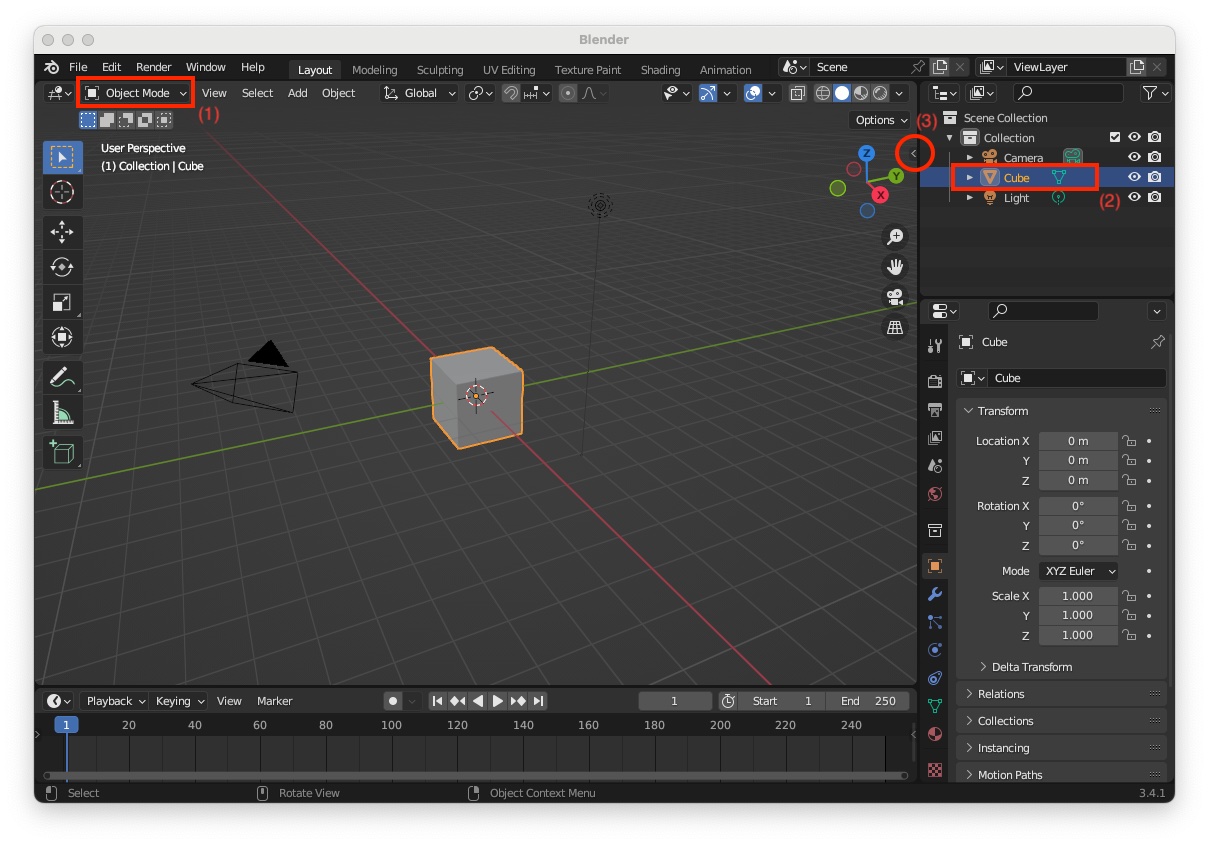
"Dimensions" to X=0.165, Y=0.068 and Z=0.08 meters (4) and change the object name to "teabox" (5). As the object's dimensions are drastically reduced, it becomes very small at the centre of the scene. "teabox" object in this is not the case (6), and rescale the object to 1. To rescale, move the mouse pointer in the scene near the box, press shortcut: Ctrl-A and select "Apply > Scale". At this point, you should see that the scale values are set to 1 (7). 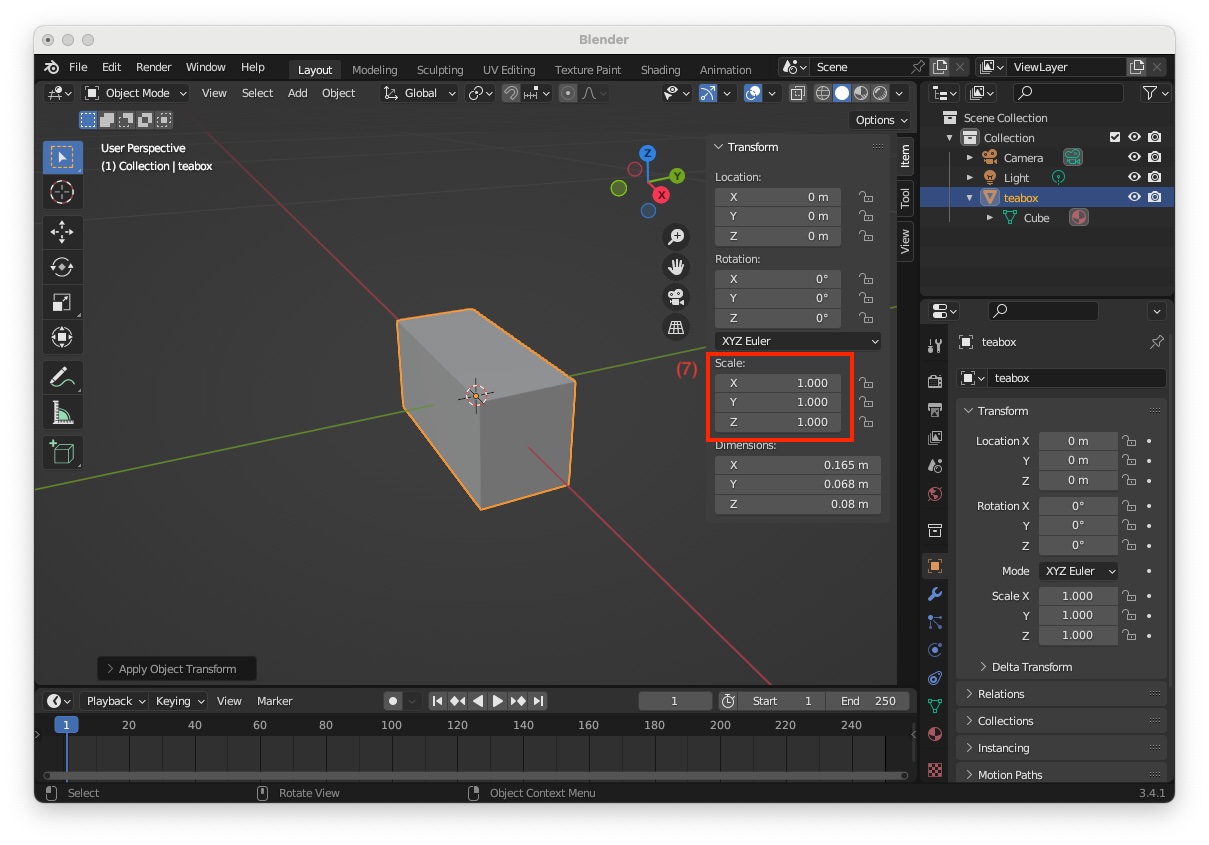
The coordinates of the box's vertices are expressed in the object frame which origin is at the box center of gravity (cog) and which axis are aligned with the scene reference frame. To conform with the required CAD model, we will move the origin of the object frame at point 0 which position is given in the next image:
"teabox" object in not the case, enter "Edit Mode" (8), select vertex corresponding to point 0 (9), press shortcut Shift-S and select "Cursor to Selected" (10) 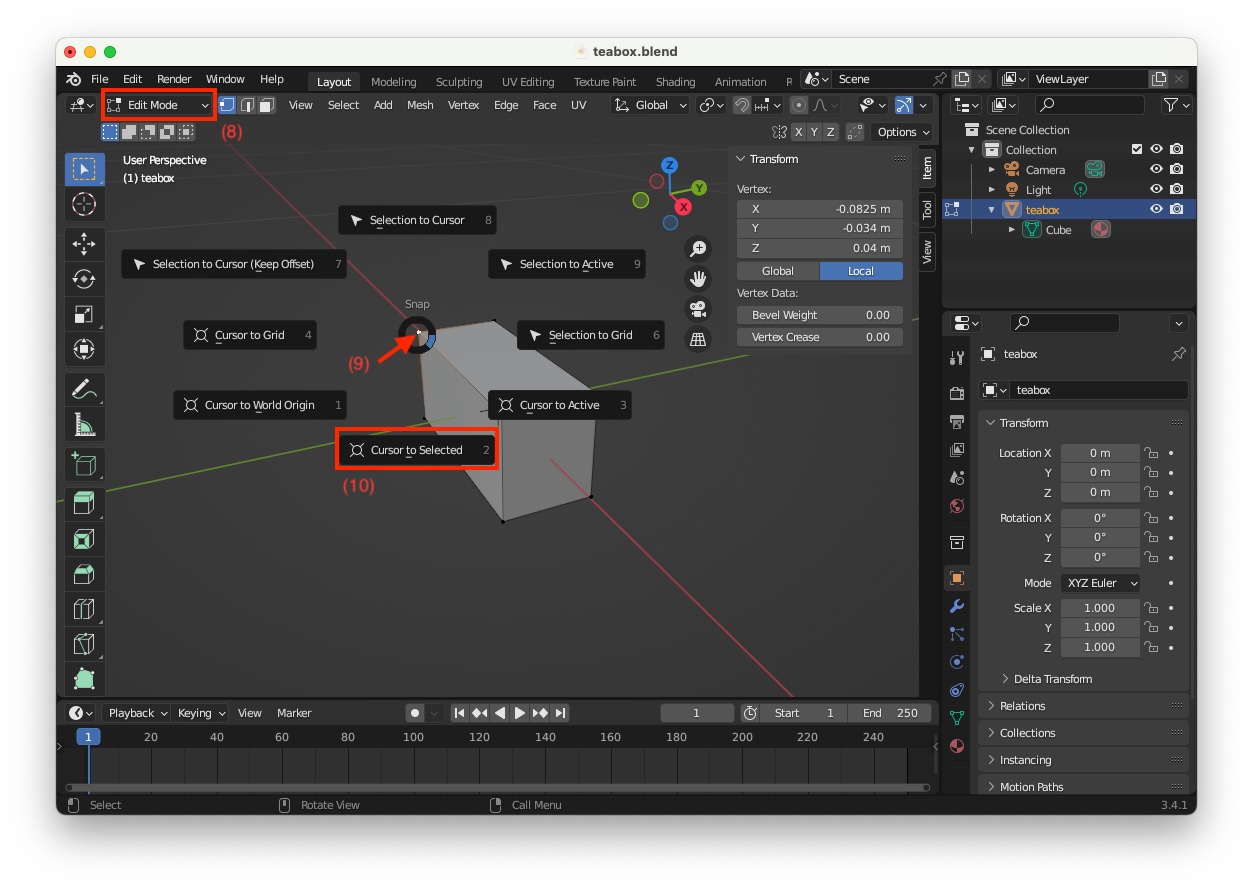
"Object Mode" (12), move the mouse pointer in the scene close to the box and press mouse right click to make appear "Object Context Menu". In this menu, select "Set Origin > Origin to 3D Cursor" (13) 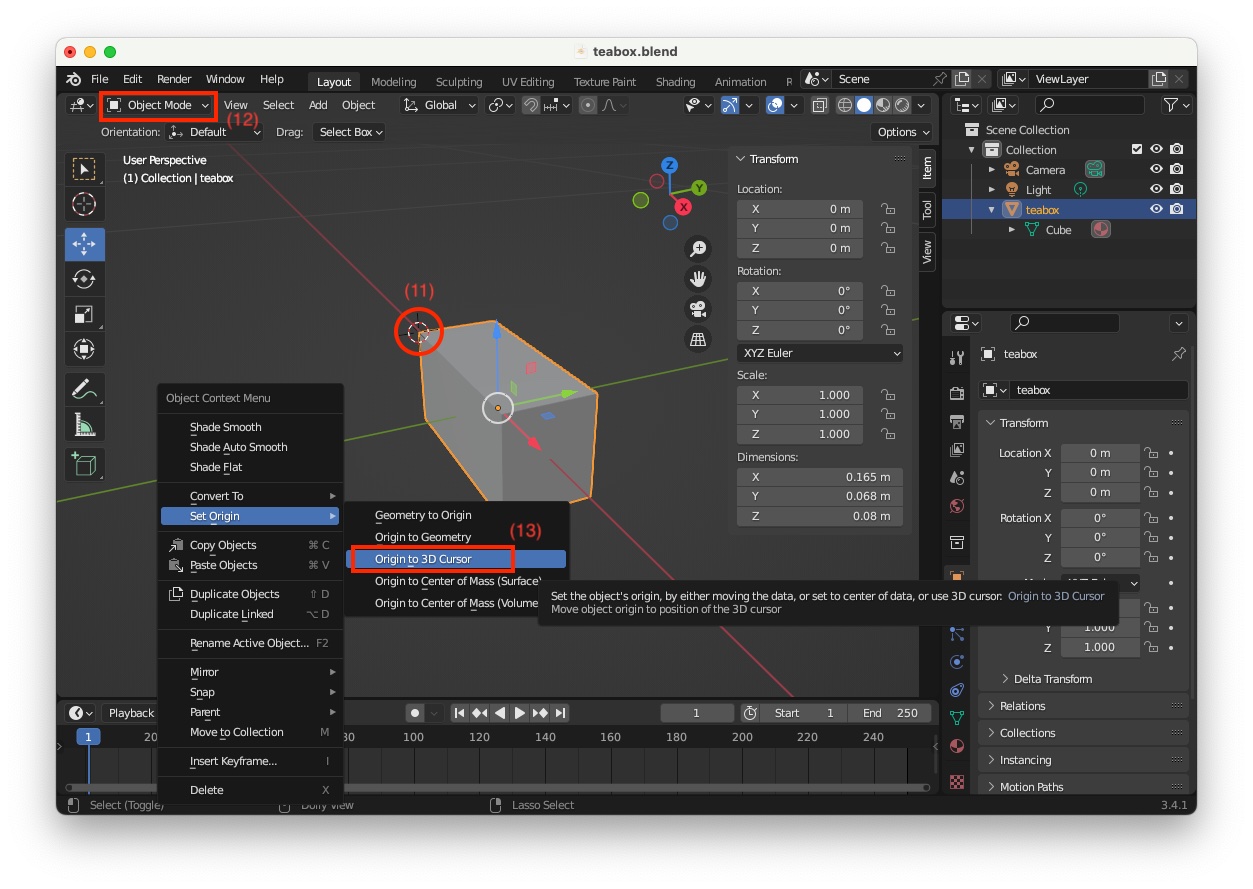
"Edit Mode" (14), select the corresponding vertex (15) to see its coordinates (16) 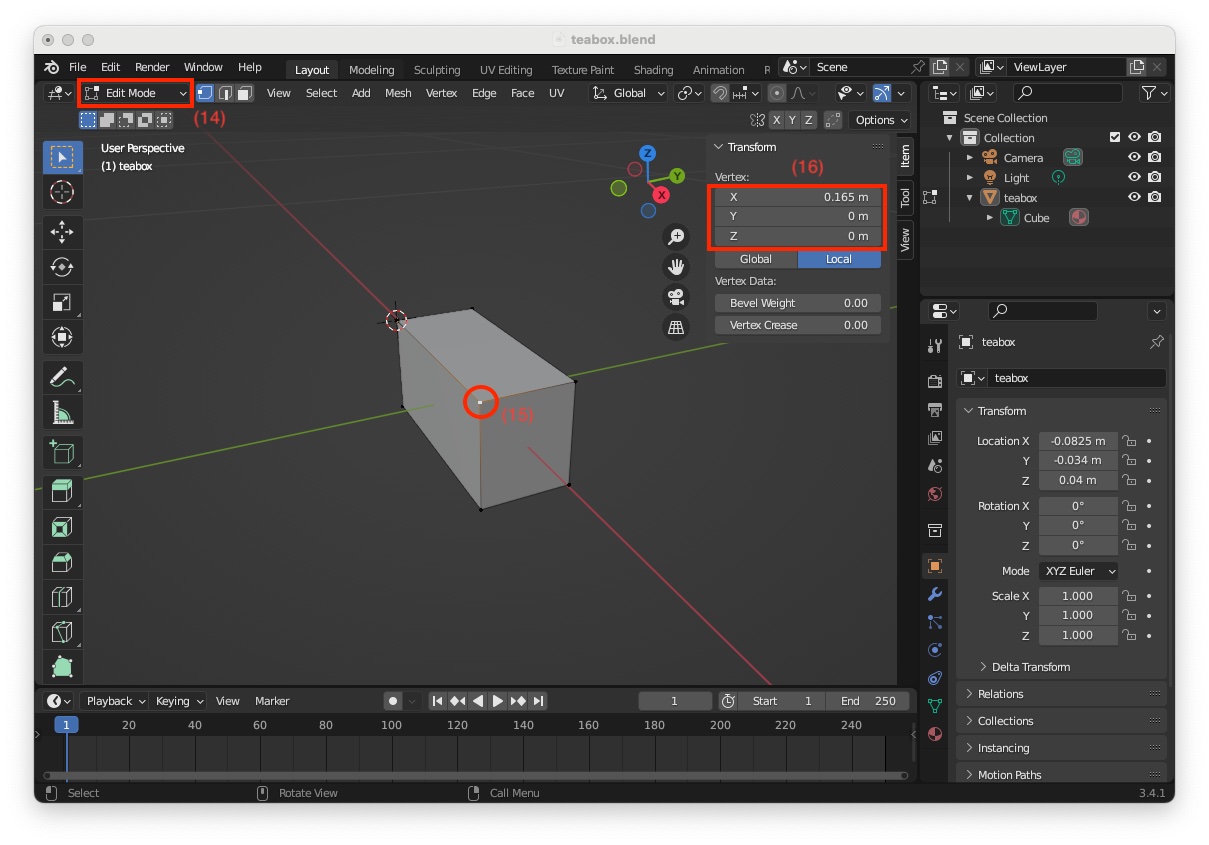
"teabox.cao" file Next step consists in adding a texture to be able to test tracking with keypoint features. You can add a realistic texture using an image texture, but here again, to simplify this tutorial, we will just add a "Voronoi Texture". To this end:
"Object Mode" (1)"Viewport Shading with Material Preview" icon (2)"Material Properties" icon (3)"Base Color" (4) 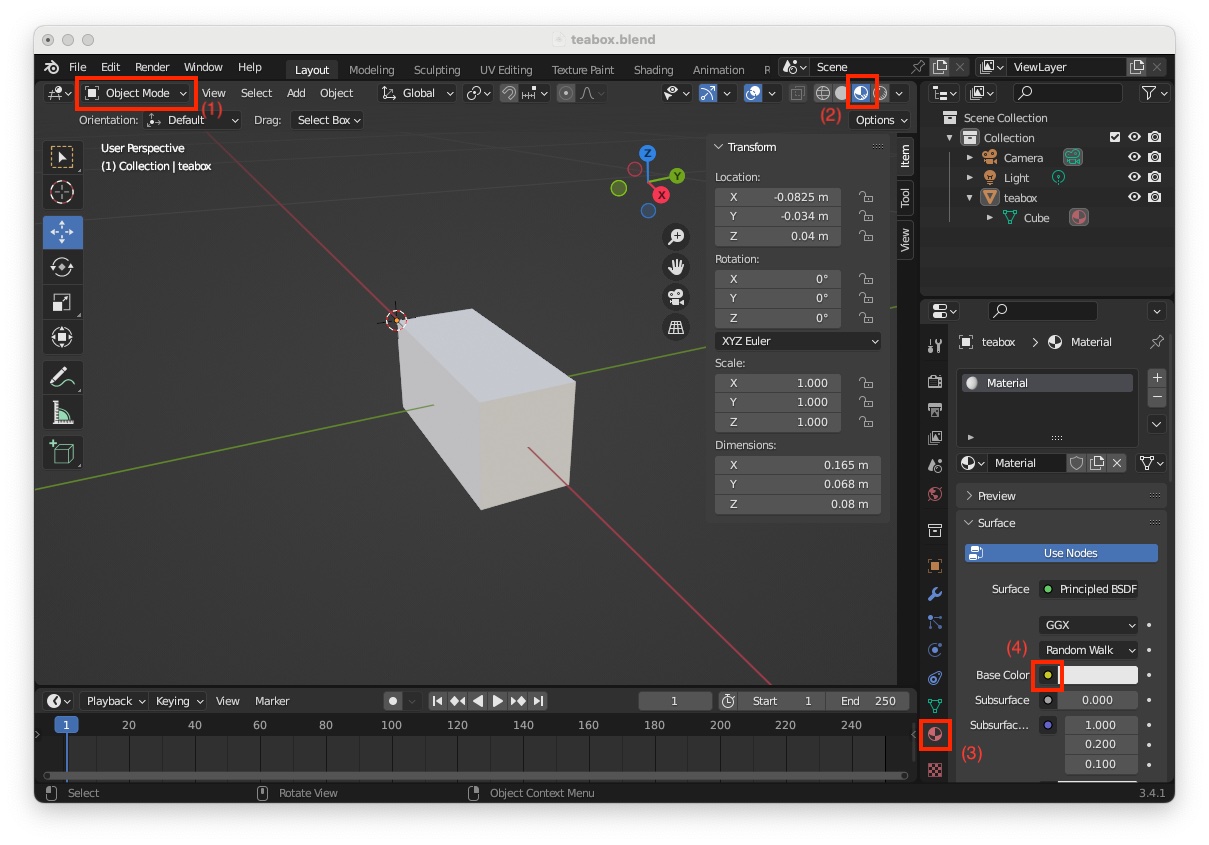
"Voronoi Texture" (5) 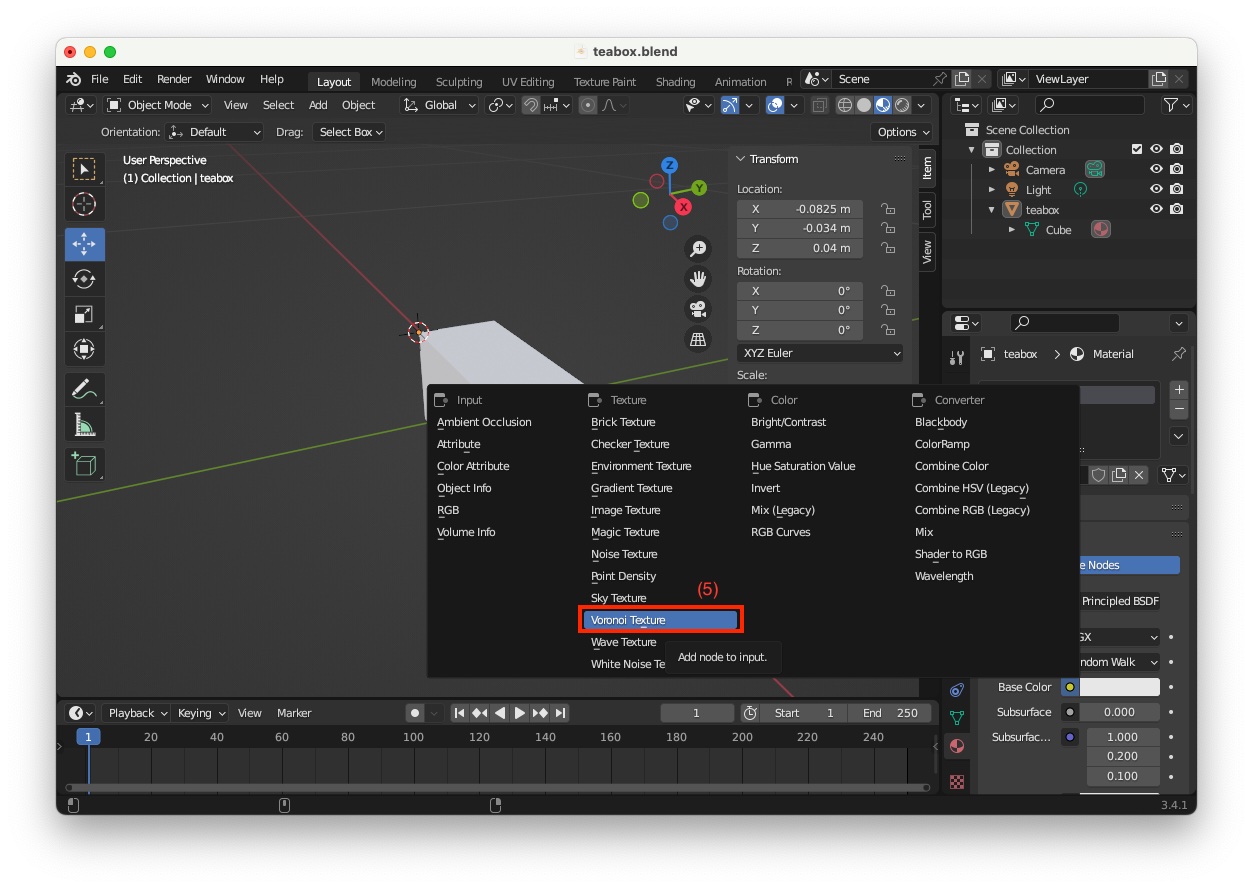
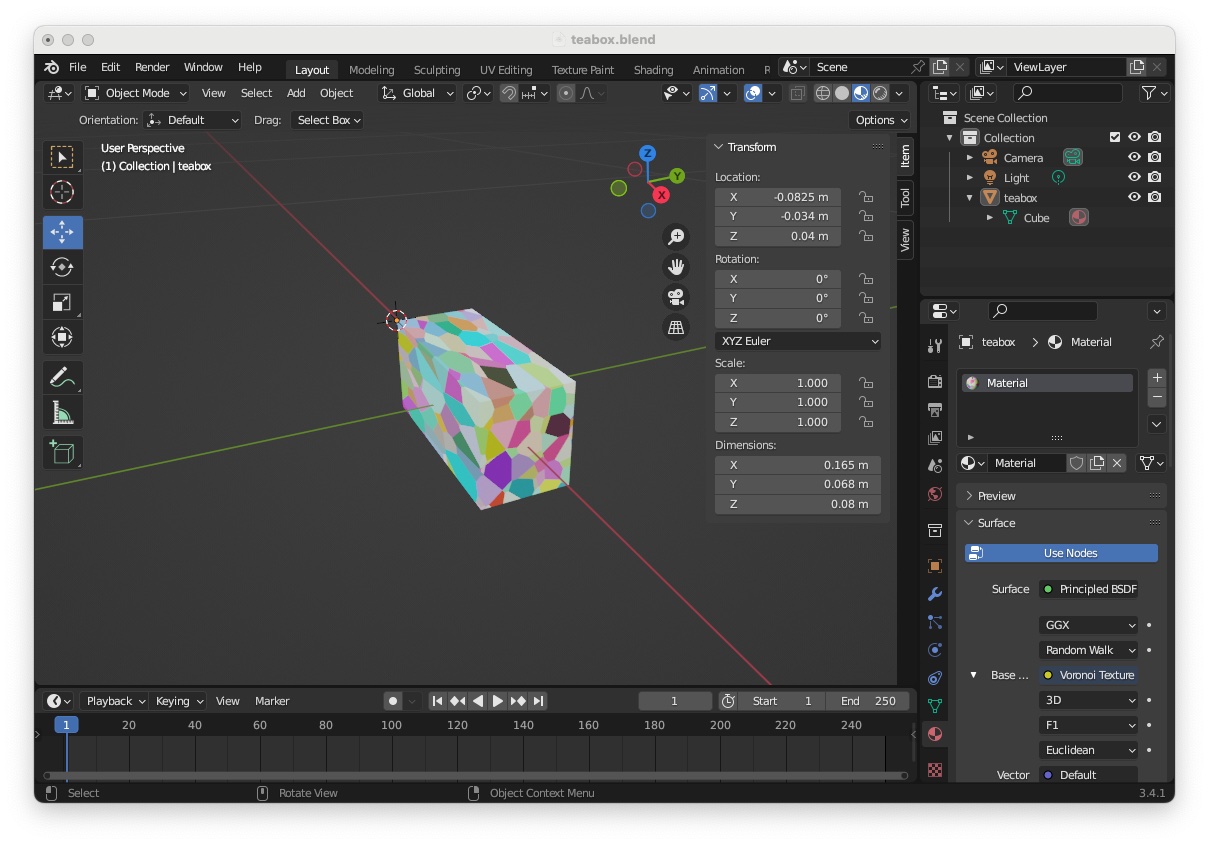
This ends the creation of a textured box that matches the "teabox.cao" cad model.
Here you will set the color camera image resolution to 640x480 to match a VGA camera resolution, set the focal length to f = 35 mm, and the sensor size to 32 mm x 24 mm. Note that the width / height ratio must be the same for the image resolution and the sensor resolution. The values we use correspond to a ratio of 4/3.
We consider now that the "Camera" that is already in the scene is the left camera. To modify its settings:
"Camera_L" (1)"Camera" menu and change "Sensor Fit" to "Vertical" and set sensor"Width"to 32 mm and sensor "Height"` to 24 mm (4) 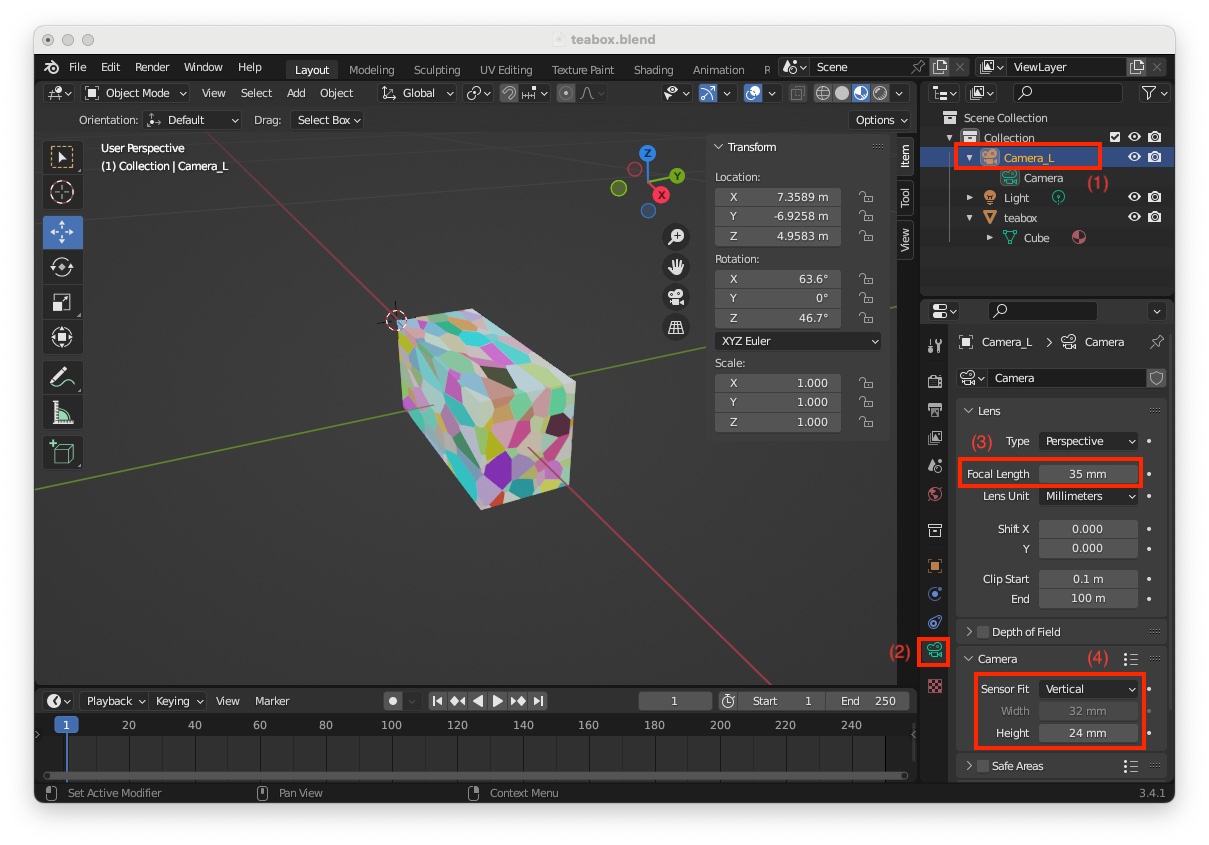
Now to set image resolution to 640x480
"Output Properties" icon (5)"Resolution X" to 640 and "Resolution Y" to 480 (6) 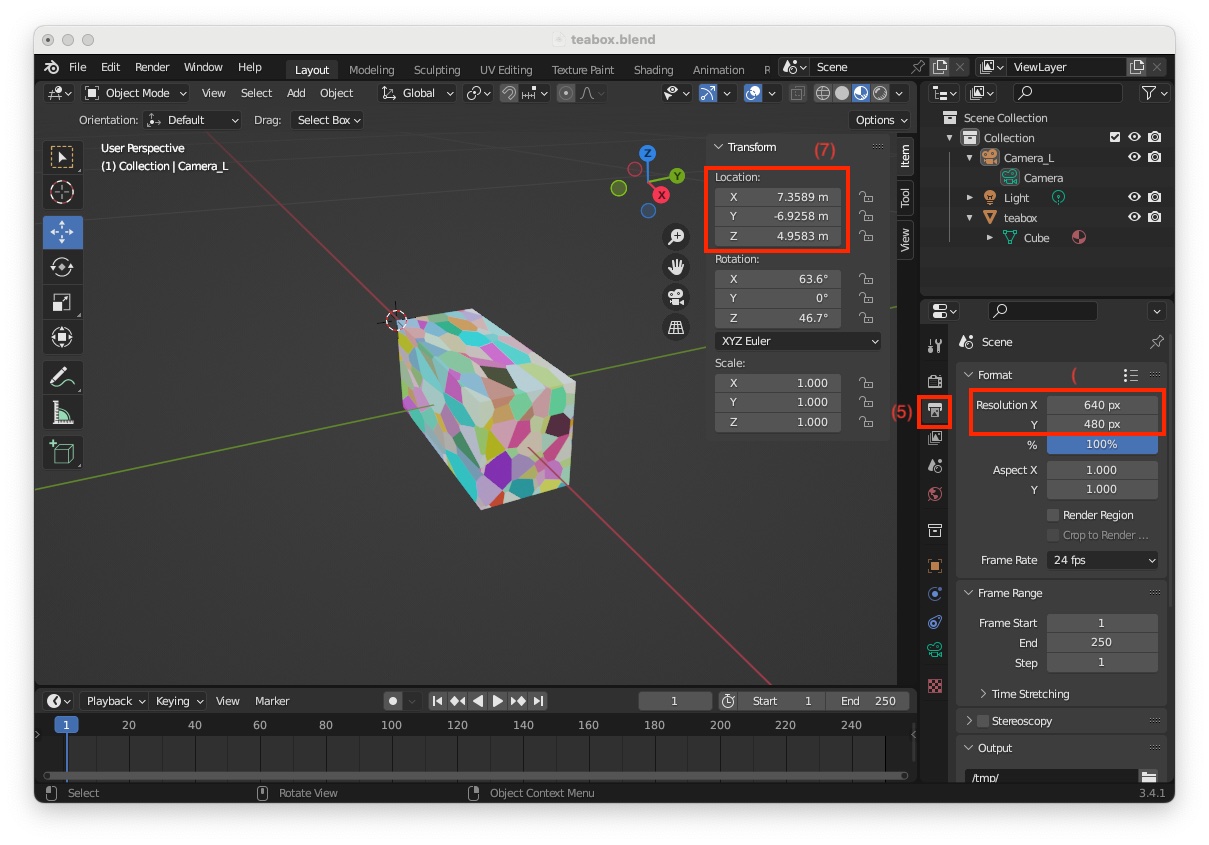
As shown in the previous image, the camera is not visible in the scene. This is simply due to its location that is too far from the scene origin. The camera frame origin is exactly at location X = 7.3589, Y = -6.9258, Z = 4.9583 meters (7). We need to move the camera close to the object and choose a position that will ease introduction of the depth camera.
To this end:
"Transform" panel, modify its "Location" to X = 0, Y = -0.35, Z = 0.3 meters, its "Rotation" to X = 45, Y = 0, Z = 0 deg, and its "Scale" to X = 0.050, Y = 0.050, Z = 0.050 (8)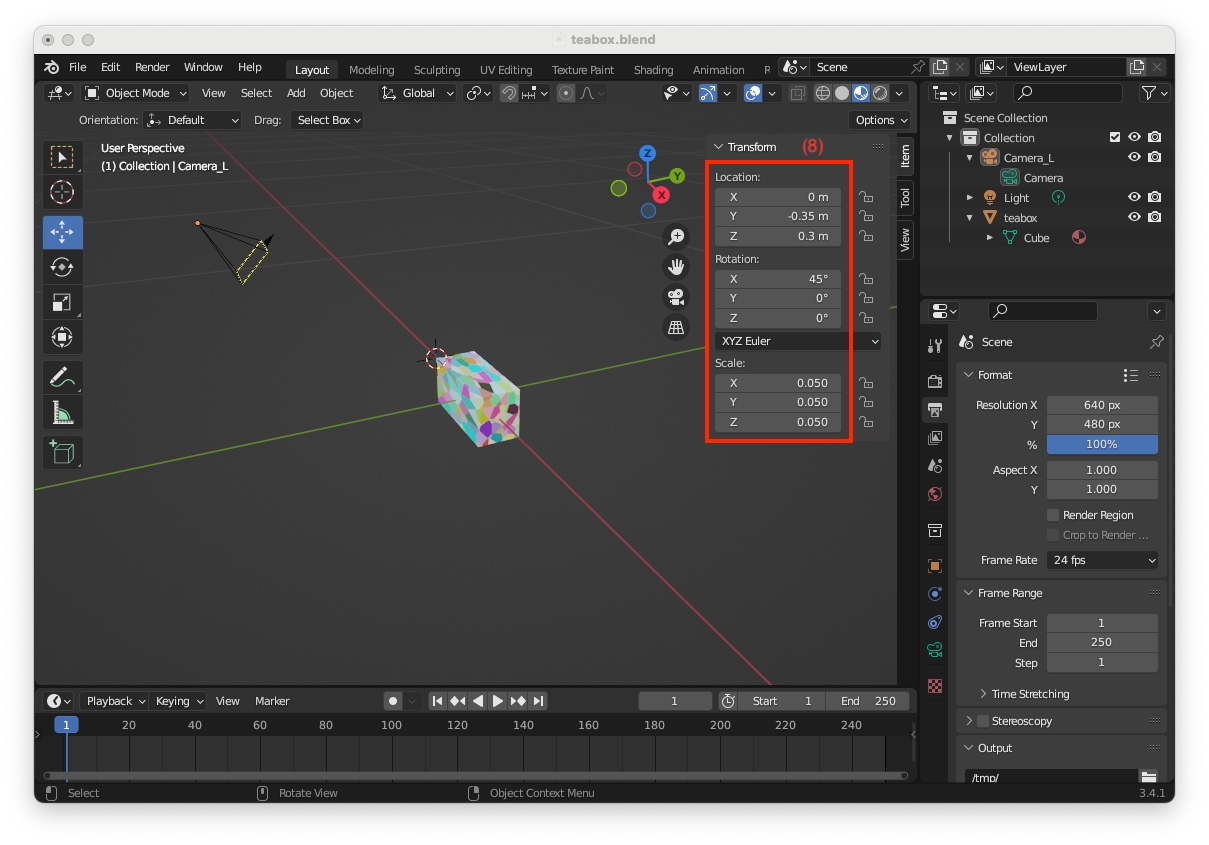
For curiosity you can now render an image of your object (shortcut: F12) and obtain an image like the following:
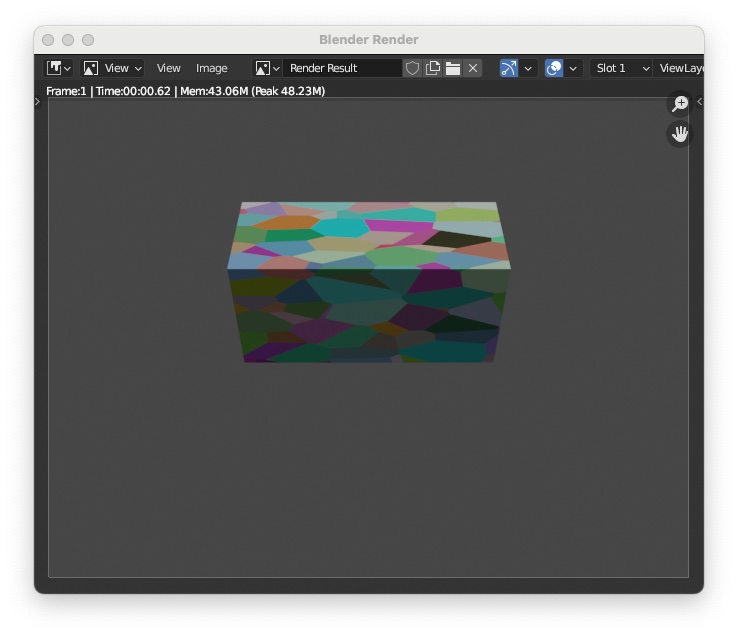
To simulate an RGB-D camera, we need to add a second camera to retrieve the depth map and set the appropriate parameters to match the desired intrinsic parameters following the same instructions as in previous section. To this end:
"3D Viewport" (shortcut: Shift-F5)"Add > Camera" (1)"Scene Collection" the new camera appears with name "Camera" (2)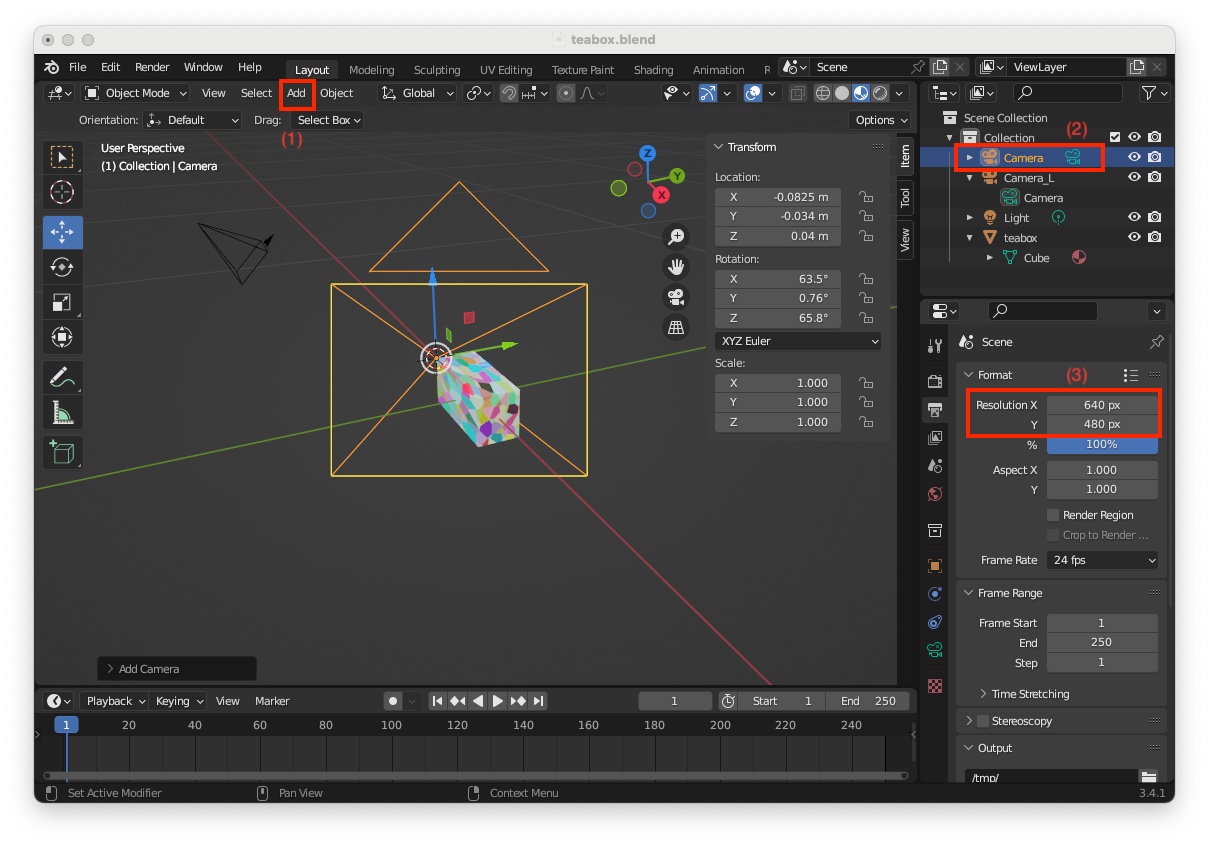
We need now to modify its settings to match the required intrinsics:
"Camera_R" (4)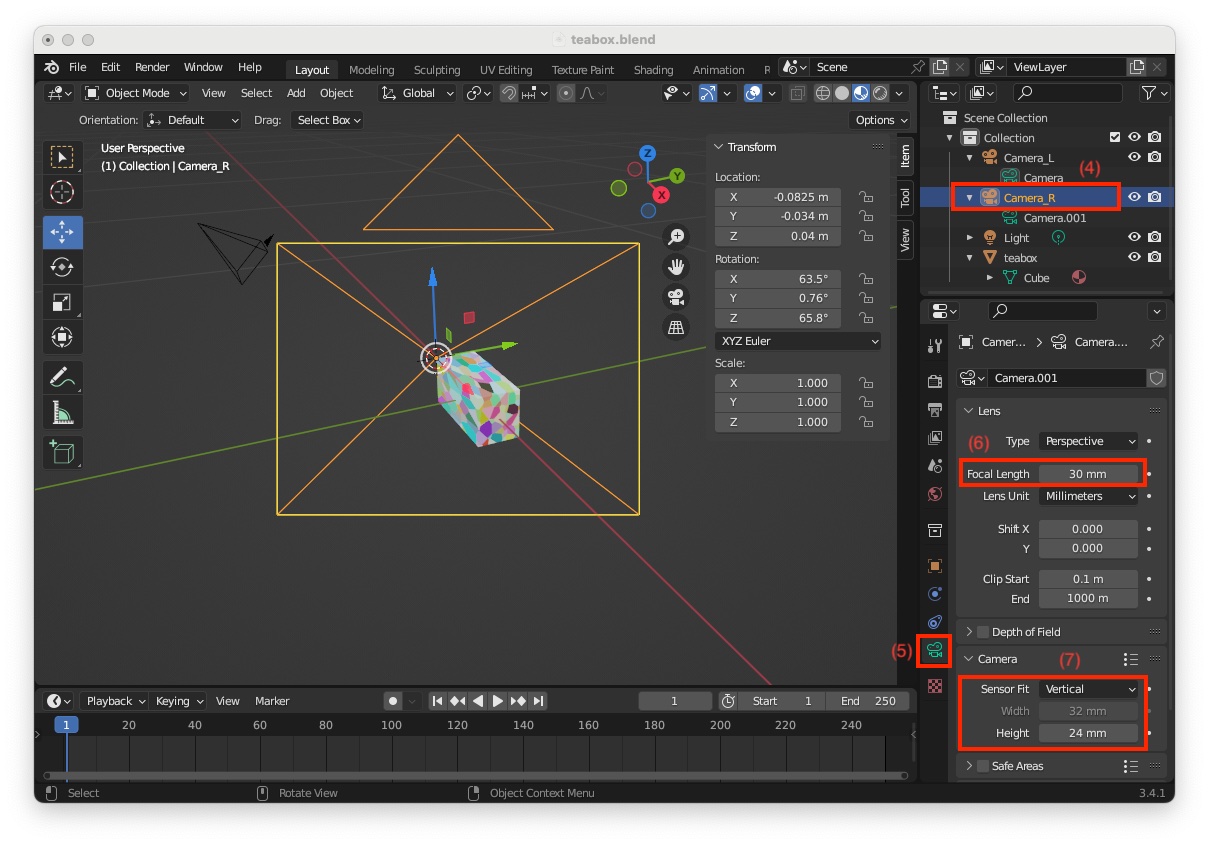
Since this depth camera should be 10 cm on the right of the color camera, we need to modify its location:
"Camera_R" corresponding to the depth camera is selected (8)In the"Transform"panel, modify its"Location"to X = 0.1, Y = -0.35, Z = 0.3 meters, its"Rotation" to X = 45, Y = 0, Z = 0 deg, and its"Scale"` to X = 0.050, Y = 0.050, Z = 0.050 (9) 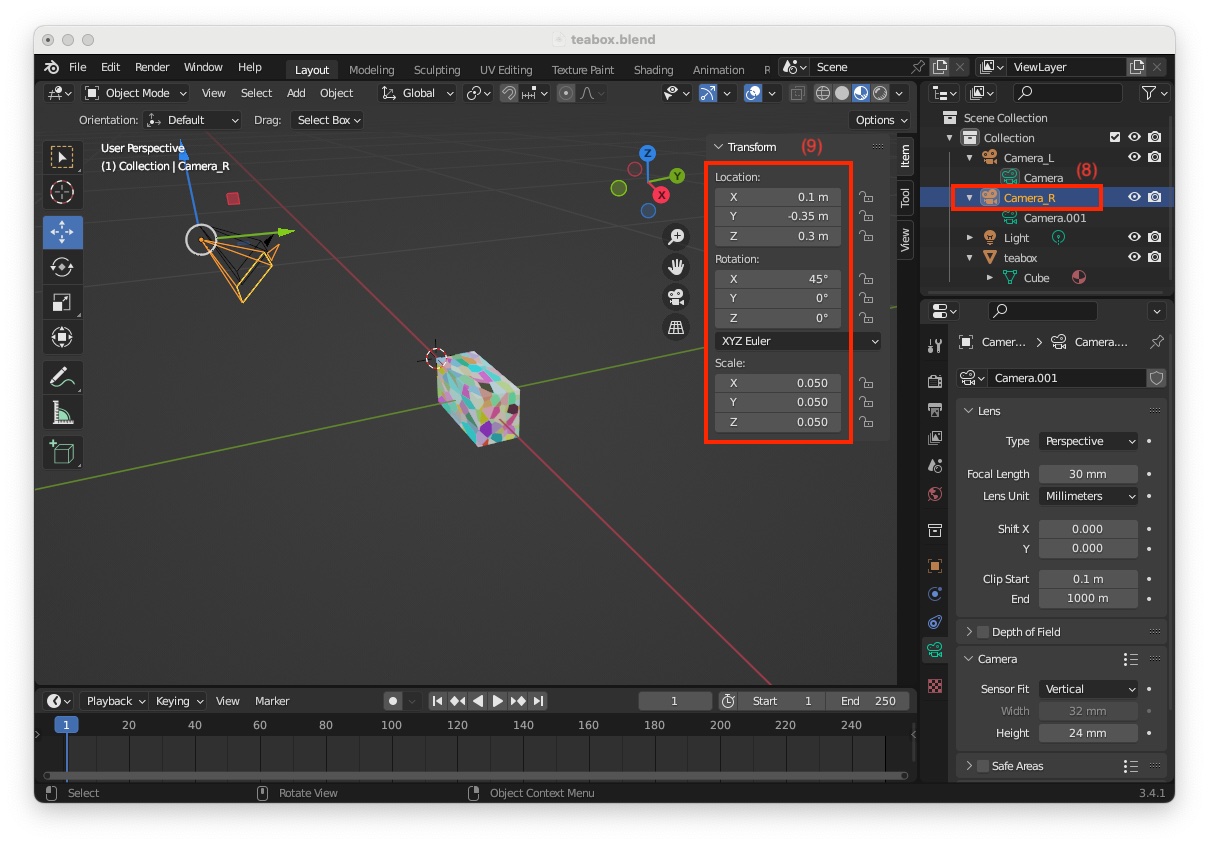
As we want to be able to animate the movement of the stereo pair rather than each camera individually, we need to link them together using the Blender parenting concept:
"Scene Collection" select "Camera_R" that will be the child object (10)"Camera_L" that will be the parent object (11)"Object" (13) 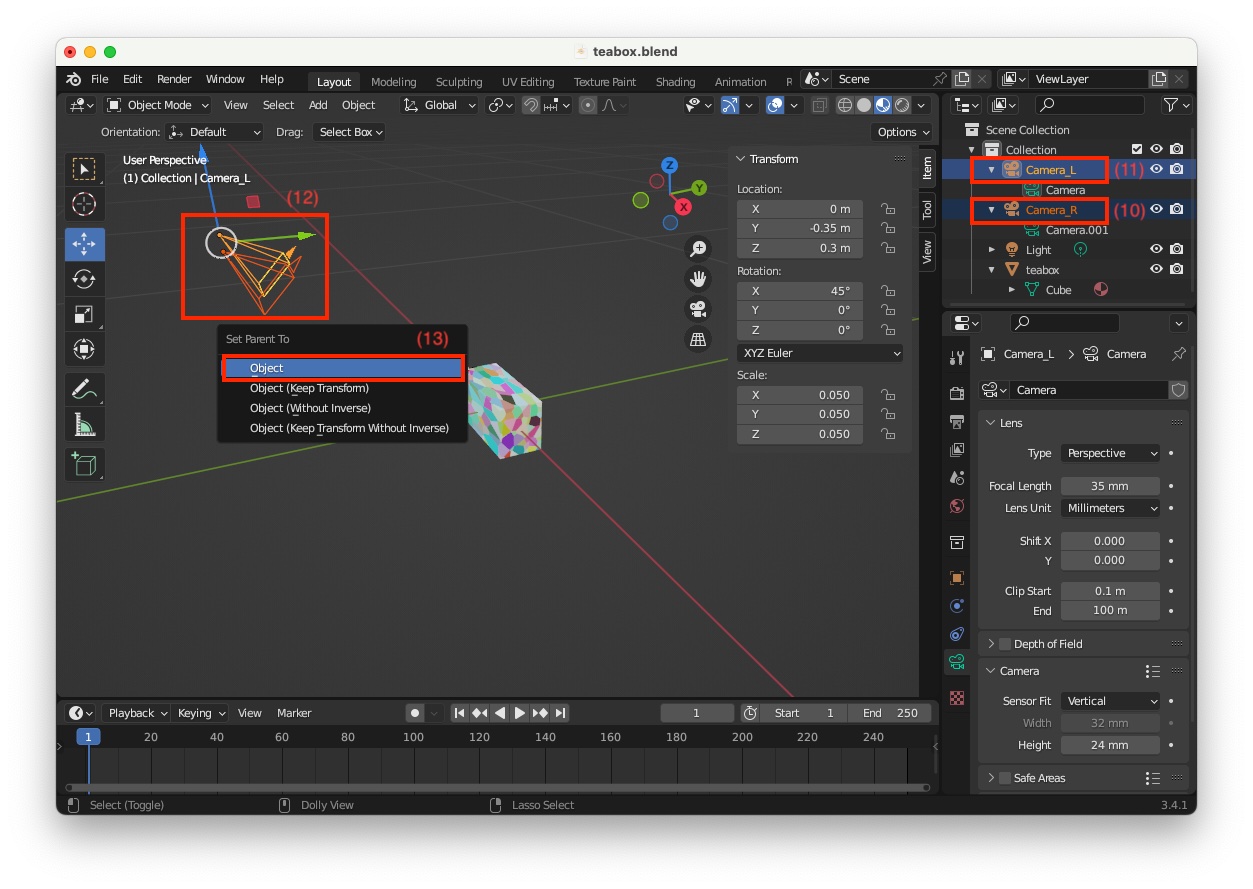
"Camera_L" has for child "Camera_L" (14) 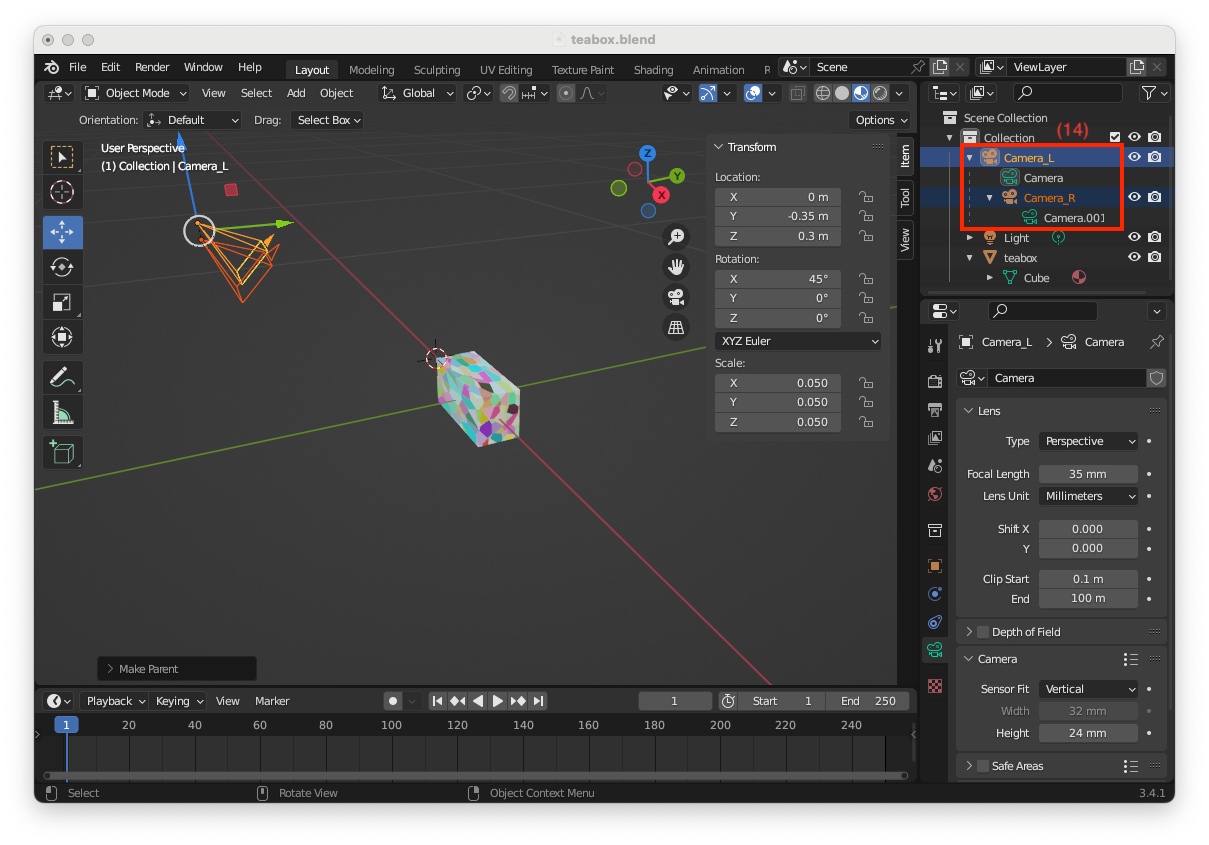
If you enter menu "Render > Render Image" you will see only the box seen by the color left camera. To be able to render color and depth, you need to enable "Stereoscopy". To this end:
"Output Properties" icon (1)"Stereoscopy" (2) 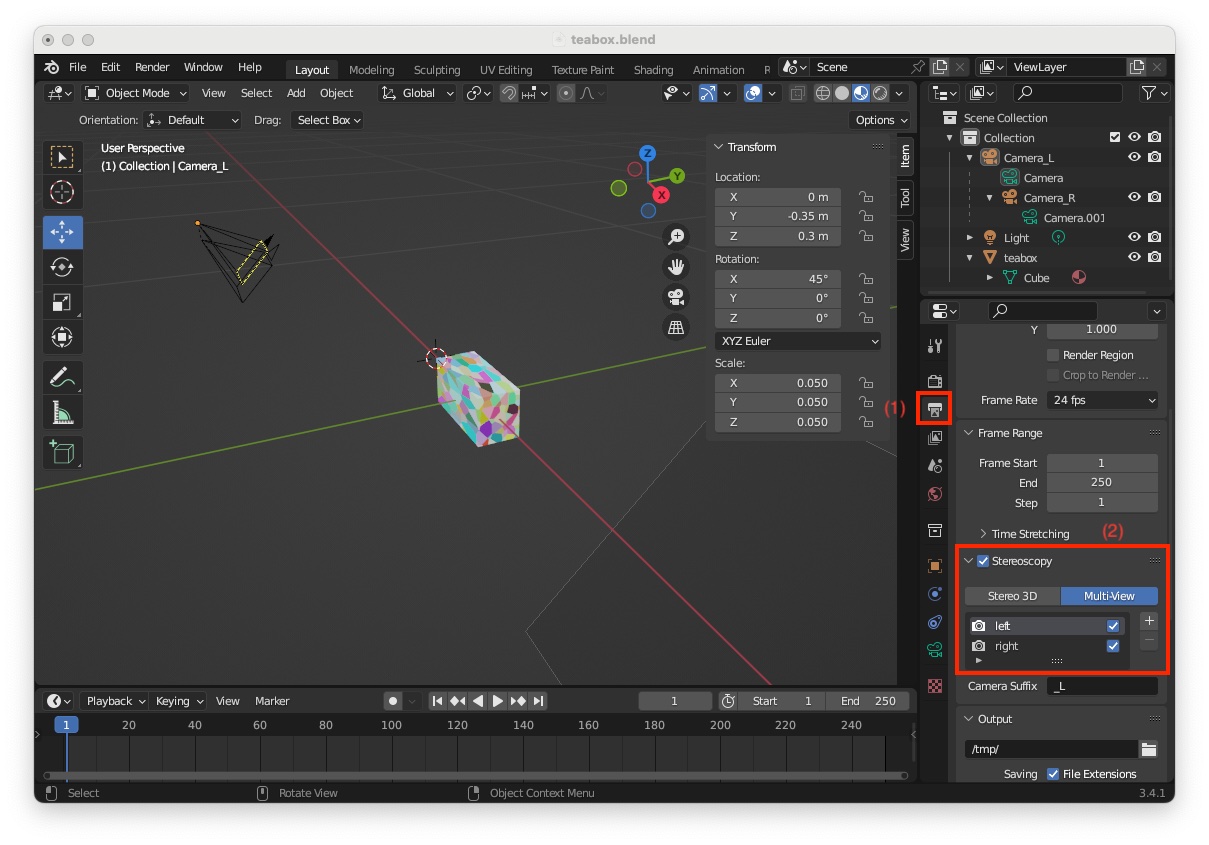
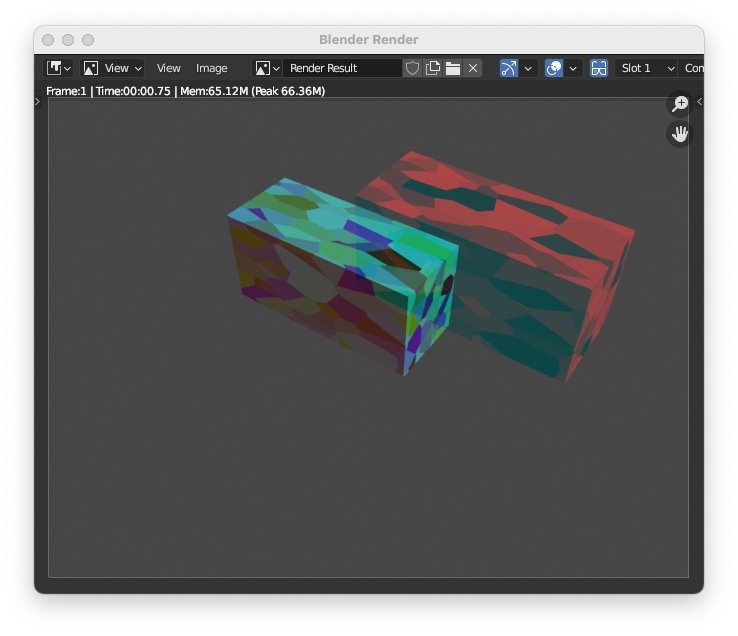
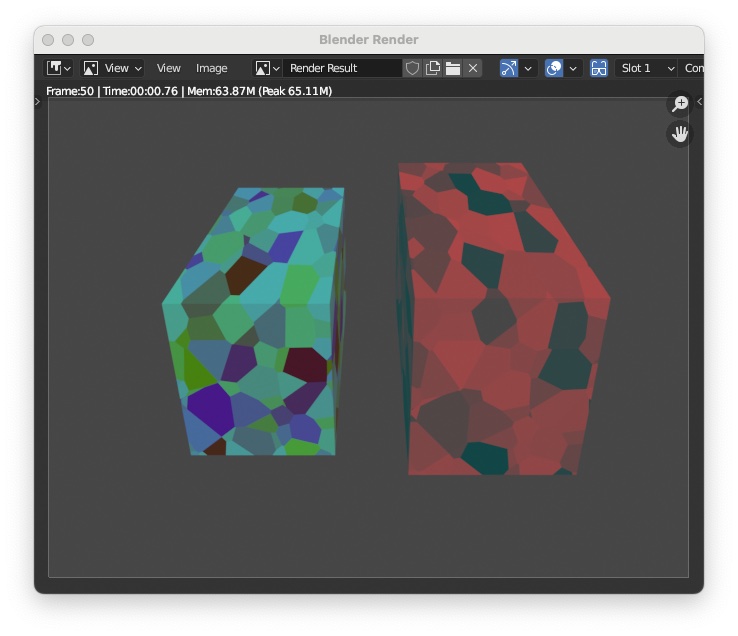
"Render > Render Image" you will see the box rendered by the left camera and right camera like the following image 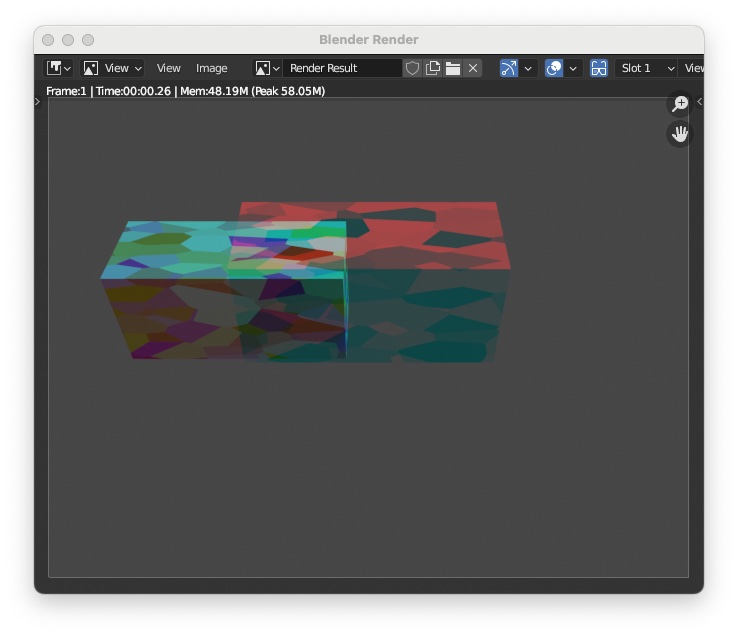
The last thing to do is to modify the project to generate the depth maps. To this end:
"View Layer Properties" icon (3)"Data > Z" (4) 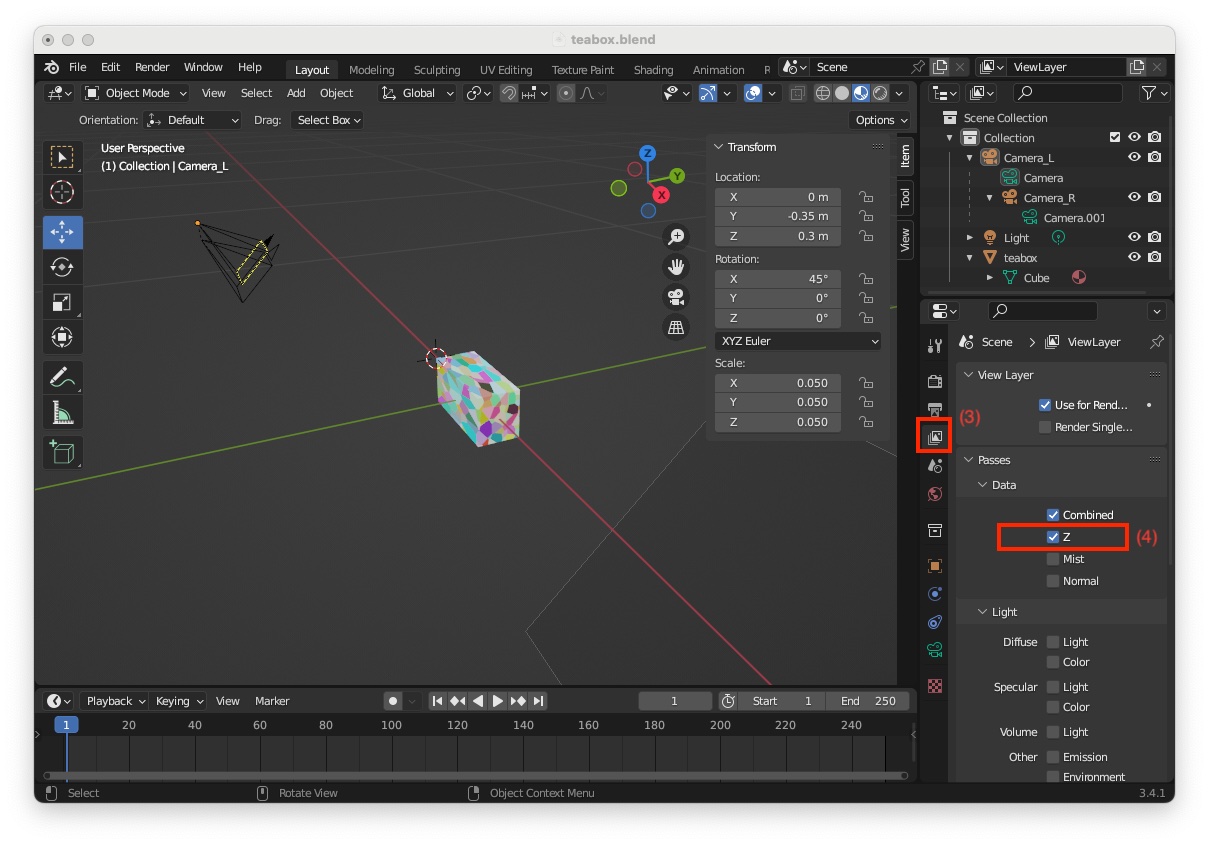
Now we need to set the format of the depth map images that will be rendered:
"Compositor" screen layout, next to the menu bar (shortcut: Shift-F3)"Use Nodes" (5) and "Backdrop" (6)"Add > Output > File Output" to add file output node (7)"Depth" output of the "Render Layers" node to the "File Output" node (8)"Base Path" to "/tmp/teabox/depth" the name of the folder that will host rendered depth maps (9)"Node" tab (10)"File Format" to OpenEXR (11) 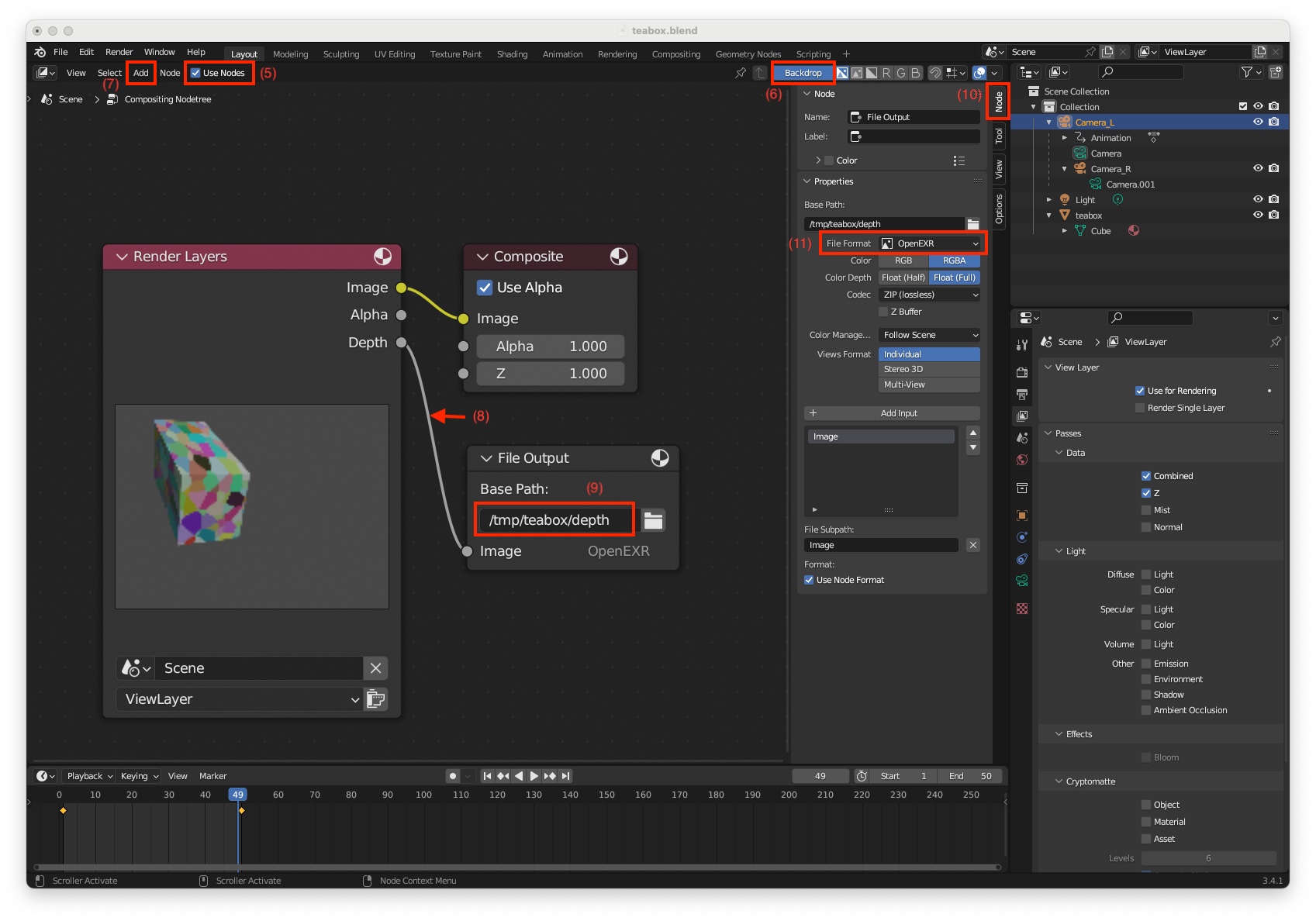
Now if you render an image using menu "Render > Render Image" in "/tmp/teabox/depth" folder you will get depth images for the left and right cameras. There is nos possibility to enable depth only for the right camera. Depth images corresponding to the left camera could be removed manually.
We are now ready to animate the scene. First we have to define the camera initial position. This can be done easily:
"3D Vieport" (shortcut: Shift-F5)"Camera_L" (1)"Move" (2) and "Rotate" (3) tools move the stereo camera at a desired initial location / orientation. You can also enter the values directly in the "Transform" panel. A possible initial "Location" is X = 0.15, Y = -0.35, Z = 0.3 meters and "Rotation" X = 45, Y = 0, Z = 35 degrees (4)"Render > Render Image" (5) to check if your object is visible in the image"Start" frame number which is 1 (6)I) and choose "Location, Rotation & Scale" to insert a keyframe at the "Start" frame with number 1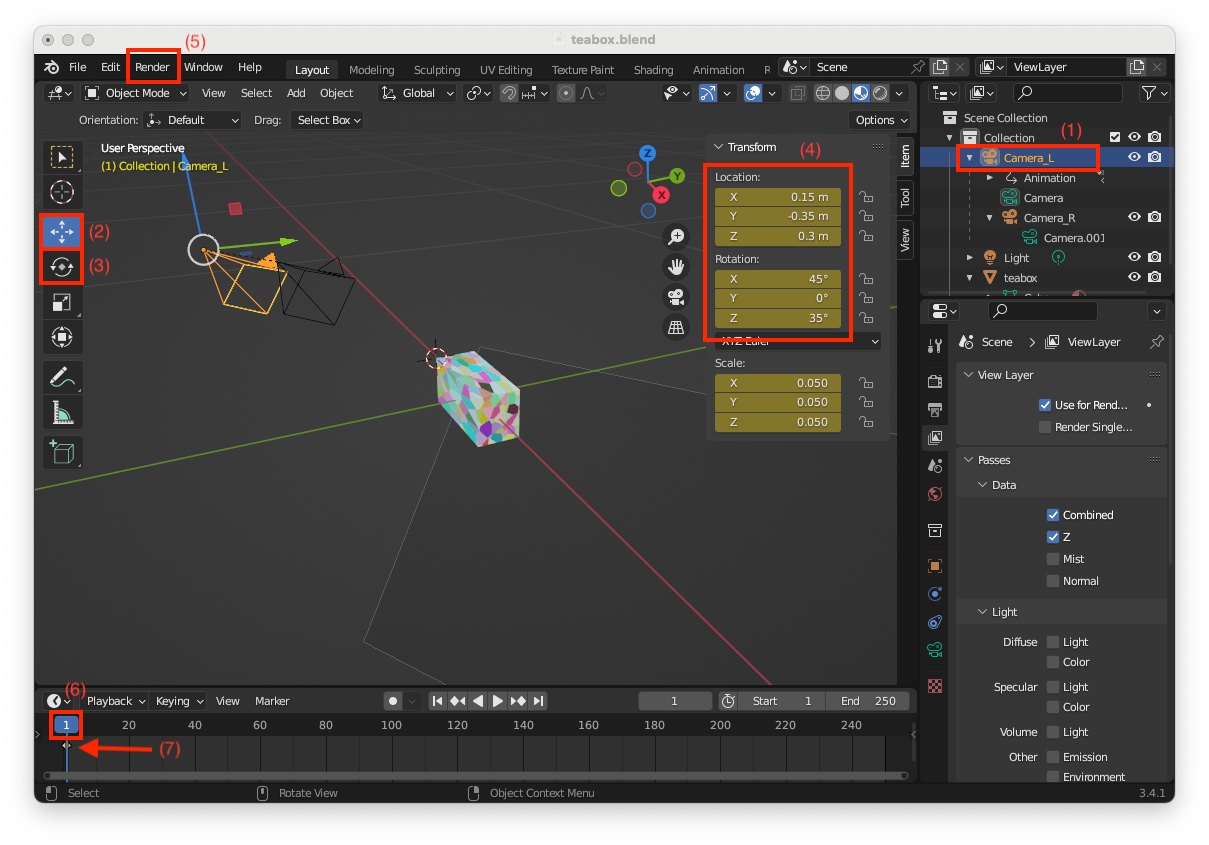
Now we have to perform the same operation for the camera final position.
"Camera_L" (8)"End" frame number of your animation. By default "End" frame is set to 250. Here we set this number to 50 (9)"End" frame number (10)"Location" X = 0.3, Y = -0.15, Z = 0.15 meters and "Rotation" X = 60, Y = -10, Z = 65 degrees (11)"Render > Render Image" (12) to check if the box is visible in the imageI) and choose "Location, Rotation & Scale" to insert a keyframe at the "End" frame with number 50"Play Animation" button (14) and see the stereo pair moving from started position to end position 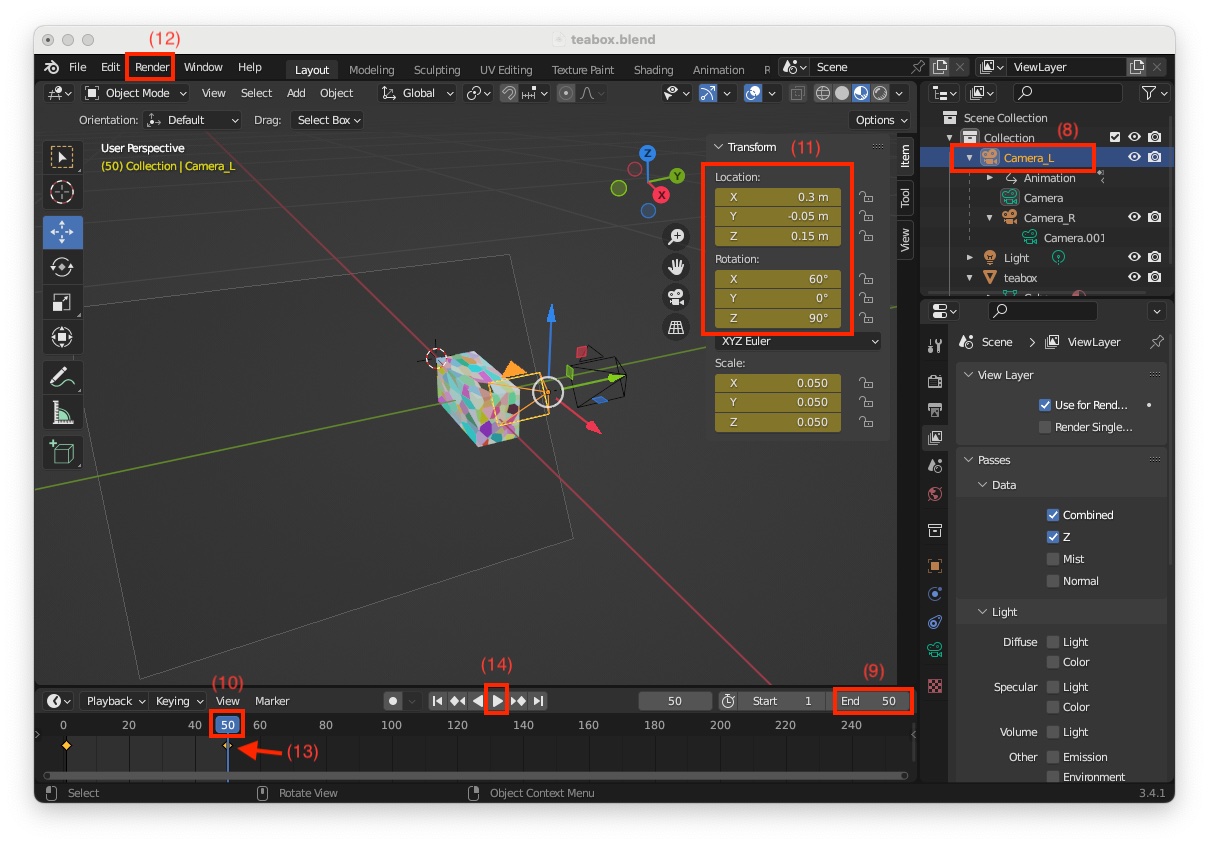
This completes the configuration of the scene in Blender. We strongly recommend that you save your project.
$VISP_WS/visp/tutorial/tracking/model-based/generic-rgbd-blender/data/teabox/blender/teabox.blend.Here we want to run get_camera_pose_teabox.py Python script inside Blender to:
"/tmp/teabox" folder"Camera_L.xml""Camera_R.xml""depth_M_color.txt""color/%04d_L.jpg" files"depth/Images%04d_R.exr" files"ground-truth/Camera_L_%04d.txt" filesThe Python script is available in "$VISP_WS/visp/tutorial/tracking/model-based/generic-rgbd-blender/" folder.
Since the script is displaying information using print() function, Blender should be started from a terminal.
Then to run the Python script in Blender:
"3D Viewport" to "Text Editor" (shortcut: Shift-F11)$VISP_WS/visp/tutorial/tracking/model-based/generic-rgbd-blender/get_camera_pose_teabox.py"Run Script" (1) (shortcut: Alt-P) 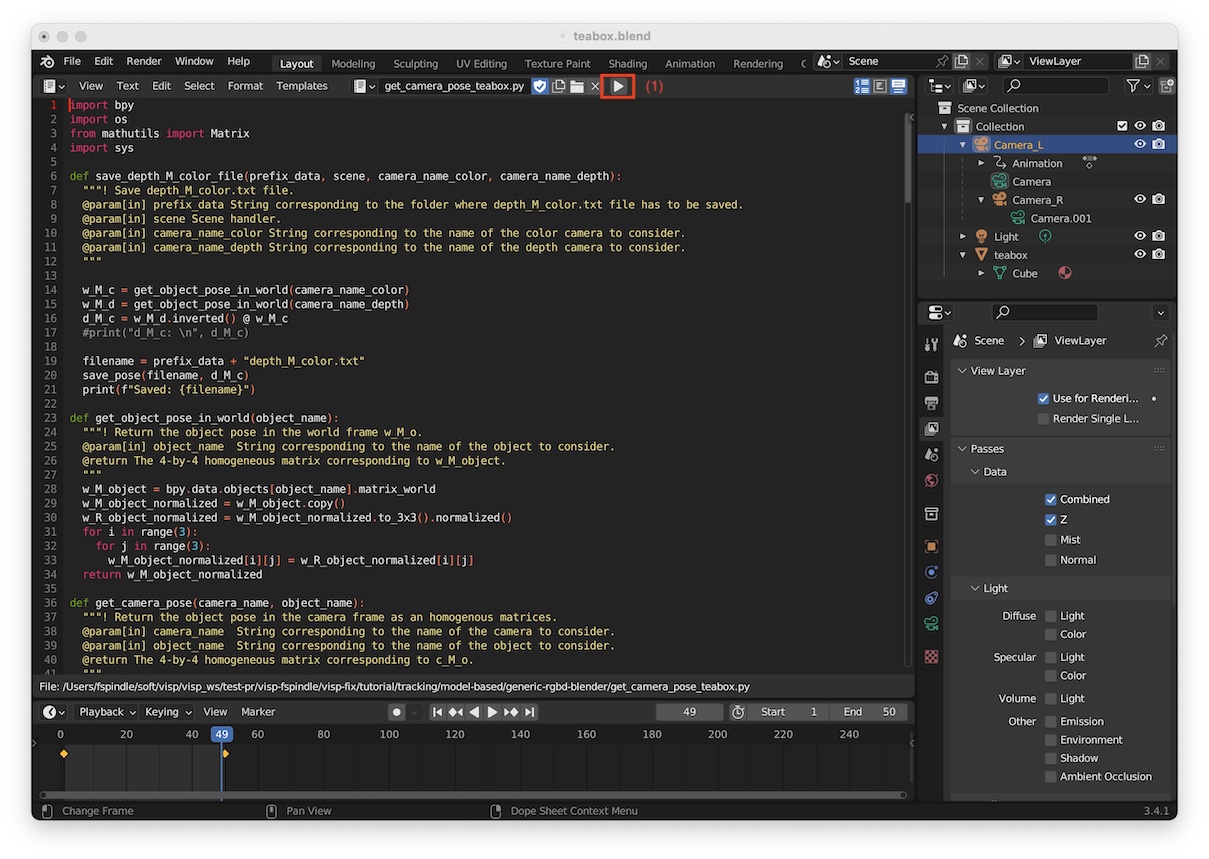
As explained previously, data are saved in the /tmp/teabox directory. By default, for each camera ("Camera_L" and "Camera_R") we render the color image and the depth image. The script will remove useless generated files by removing depth images corresponding to "Camera_L" and color images from "Camera_R".
If you are only interested to see which are the camera intrinsics of a given camera set in Blender, we provide get_camera_intrinsics.py Python script in $VISP_WS/visp/tutorial/tracking/model-based/generic-rgbd-blender/ folder.
As in the previous section, since this script is displaying information using print() function, Blender should be started from a terminal.
Then to run this Python script in Blender:
"3D Viewport" to "Text Editor" (shortcut: Shift-F11)$VISP_WS/visp/tutorial/tracking/model-based/generic-rgbd-blender/get_camera_intrinsics.py"Camera_L" "Run Script" (shortcut: Alt-P)In the terminal from which you launched Blender, you should get something similar to:
You can retrieve the depth camera intrinsics using again get_camera_intrinsics.py just by modifying in the script the name of the camera
"Camera_R" Run Script (shortcut: Alt-P)In the terminal from which you launched Blender, you should get something similar to:
The following C++ sample file also available in tutorial-mb-generic-tracker-rgbd-blender.cpp reads color and depth images, pointcloud is recreated using the depth camera intrinsic parameters. The ground truth data are read and printed along with the estimated camera pose by the model-based tracker. Since depth data are stored in OpenEXR file format, OpenCV is used for the reading.
Once build, to get tutorial-mb-generic-tracker-rgbd-blender.cpp usage, just run:
Default parameters allow to run the binary with the data provided in ViSP. Just run:
To run the binary on the data generated by Blender in "/tmp/teabox" folder, just run:
You should be able to see similar tracking results as the one given in the next video.
You are now ready to see the next Tutorial: Template tracking.