In this tutorial, we will explore how to use MegaPose [25], a deep learning method for 6D object pose estimation. To know more about MegaPose see https://megapose6d.github.io/.
Given:
An RGB or RGB-D image for which the intrinsics of the camera are known
A coarse detection of the image region in which lies the object
A 3D model of the object MegaPose can estimate the pose of the object relative to the camera frame .
The method has several advantages:
Robust estimation in the presence of occlusions and lighting artifacts
Can work with a coarse model of the object
Does not require retraining for novel objects
It has however, several drawbacks:
Running MegaPose requires a GPU. However, the integration in ViSP is based on a client-server model: MegaPose can thus run on a remote machine and its result retrieved on the local host (e.g, a computer with a CPU connected to a robot)
It may be too slow for your requirements
With the default parameters, on a 640 x 480 image, initial pose estimation takes around 2 seconds on an Nvidia Quadro RTX 6000
On the same setup, a pose update (refinement) iteration takes around 60-70 milliseconds
To perform the initial pose estimation, MegaPose requires an estimate of the image region containing the image (i.e., a bounding box detection). You may thus require a way to detect the object, such as an object detection neural network (available in ViSP with the class vpDetectorDNNOpenCV, see Tutorial: Deep learning object detection). For initial tests, the bounding box can also be provided by the user via click.
To see some results, scroll to the the end of this tutorial.
The MegaPose integration in ViSP is based on a client-server model:
The client, that uses either vpMegaPose or vpMegaPoseTracker, is C++-based. It sends pose estimation requests to the server.
The server is written in Python. It wraps around the MegaPose model. Each time a pose estimation is requested, the server reshapes the data and forwards it to MegaPose. It then sends back the information to the client.
Note
The computer running the server needs a GPU. The client can run on the same computer as the server. It can also run on another computer without a GPU. To obtain have a decent tracking speed, it is recommended to have both machines on the same network.
This tutorial will explain how to install and run MegaPose and then demonstrate its usage with a simple object tracking application.
Installation
Installing the client
The MegaPose client, written in C++, is included directly in ViSP. It can be installed on any computer, even without a GPU. To be installed and compiled, it requires:
That ViSP be compiled with the JSON third-party library, as JSON is used to pass messages. To install the 3rd party, see JSON for modern C++ installation procedure for your system. Don't forget to build ViSP again after installing JSON third-party.
Once done, ViSP should be compiled with the visp_dnn_tracker module. When generating build files with CMake, it will be built by default if the JSON third-party is detected on your system
To check that it is installed, you can check the ViSP-third-party.txt file that is generated by CMake:
$ cd $VISP_WS/visp-build
$ grep "To be built" ViSP-third-party.txt
To be built: core dnn_tracker gui imgproc io java_bindings_generator klt me sensor ar blob robot visual_features vs vision detection mbt tt tt_mi
If "dnn_tracker" is in the list, then the client can be compiled and used.
Otherwise it means that ViSP is not built with JSON third-party:
$ cd $VISP_WS/visp-build
$ grep "json" ViSP-third-party.txt
Use json (nlohmann): no
As explained previously, see JSON for modern C++ installation procedure and build again ViSP.
Installing the server
Warning
The megapose server cannot directly be installed and used on Windows. A workaround is to install it in a WSL container. A WSL container works as a Linux (Ubuntu) distribution. The client still works on Windows, and WSL allows for port forwarding, making its usage seamless from the perspective of the client.
MegaPose server should be installed on a computer equipped with a GPU. To install the MegaPose server, there are two dependencies:
Conda: MegaPose will be installed in a new virtual environment in order to avoid potential conflicts with python and other packages you have already installed
To install conda on your system, we recommend miniconda, a minimal version of conda. To install, see the miniconda documentation
Once installed, make sure that conda is in your environment path variable. The conda installation procedure should do this by default.
To check, simply enter conda --version in your terminal.
You should obtain an output similar to:
$ conda --version
conda 23.3.1
Git is also required in order to fetch the MegaPose sources. If you built ViSP from sources, then it should already be installed.
The server sources are located in the $VISP_WS/visp/script/megapose_server folder of your ViSP source directory.
In this folder, you can find multiple files:
run.py: the code for the server
install.py: the installation script
megapose_variables.json: configuration variables, used in the installation process.
To start the installation process, you should first set the variables in megapose_variables.json file:
environment: name of the conda environment that will be created. By default, the environment name is set to "megapose". The MegaPose server will be installed in this environment and it should thus be activated before trying to start the server. For example, if you set this variable to "visp_megapose_server", then you can activate it with:
$ conda activate visp_megapose_server
megapose_dir: the folder where MegaPose will be installed. By default, the installation folder is set to "./megapose6d"
megapose_data_dir: the folder where the MegaPose deep learning models will be downloaded. By default, the data will be downloaded in "megapose" folder.
Once you have configured these variables: run the installation script with:
$ cd $VISP_WS/visp/script/megapose_server
$ python install.py
The script may run for a few minutes, as it downloads all the dependencies as well as the deep learning models that MegaPose requires.
Once the script has finished, you can check the installation status with the following commands where <name_of_your_environment> could be replaced by megapose if you didn't change the content of megapose_variables.json file:
$ conda activate <name_of_your_environment>
$ python -m megapose_server.run -h
The -h argument should print some documentation on the arguments that can be passed to the server.
With MegaPose installed, you are now ready to run a basic, single object tracking example.
Single object tracking with MegaPose
In this tutorial, we will track an object from a live camera feed. For MegaPose to work, we will need:
The 3D model of the object
A way to detect the object in the image
A machine with a GPU, that hosts the server. If your machine has a GPU, then you can run the server and this client in parallel.
To get you started, we provide the full data to run tracking on a short video. To go further, you should check Adapting this tutorial for your use case that will explain what you need to use your own objects and camera.
Starting the server
To use MegaPose, we first need to start the inference server. As we have installed the server in Installing the server, we can now use it from anywhere. First, activate your conda environment:
$ conda activate megapose
where megapose is the name of the conda environment that you have defined in megapose_variables.json file when installing the server.
We can now start the server, and examine its arguments with:
Directory containing the 3D models. each 3D model must be
in its own subfolder
--optimize Experimental: Optimize network for inference speed.
This may incur a loss of accuracy.
--num-workers NUM_WORKERS
Number of workers for rendering
From the multiple arguments described, the required ones are:
--host: the IP address on which the server will listen. If you plan to run the tracking example and the MegaPose server on the same machine, use 127.0.0.1. If running on separate machines, you can find out the IP address of the server with:
On Linux (with the net-tools package)
$ ifconfig
and look for the inet field of the network interface that can be reached by the client.
On Windows
C:> ipconfig /all
--port: The port on which the server will listen for incoming connections. This port should not already be in use by another program
--model: The model that is used to estimate the pose. The available options are:
RGB: This model expects an RGB image as an input. From the coarse model estimates, the best pose hypothesis is given to the refiner, which performs 5 iterations by default.
RGBD: Same as above, except that an RGBD image is expected in input. Using RGBD is not recommended for tracking applications, as the model is sensitive to depth noise.
RGB-multi-hypothesis: Same as RGB, except that the coarse model selects the top-K hypotheses (Here, K = 5) which are all forwarded to the refiner model. This model will take far more time, and is thus not recommended for tracking, but may be useful for single shot pose estimation if you have no speed requirements.
RGBD-multi-hypothesis: Is similar to RGB-multi-hypothesis, except that ICP after the refiner model has run on RGB images. This model thus requires an RGBD image.
--meshes-directory: The directory containing the 3D models. The supported format are .obj, .gltf and .glb. If your model is in another format, e.g., .stl, it can be converted through Blender The directory containing the models should be structured as follow:
models
|--cube
|--cube.obj
|--cube.mtl
|--texture.jpg
|--my_obj
|--object.glb
In the example above, if we start the server with the meshes-directory set to models, two objects should be recognized: cube and my_obj. The name of an object is dictated by its folder name.
To run the basic version of the tutorial below, we provide the model of the cube that is to be tracked in the video. The 3D models directory is data/model, located in the tutorial folder. To start the server, you should enter in your terminal:
(megapose) $ cd $VISP_WS/visp-build/tutorial/tracking/dnn
Note that this assumes that your current directory is the tutorial folder.
Warning
If you are running on Windows through WSL, you may encounter an error mentioning that a CUDA/CUDNN-related .so file is not found. To resolve this issue, enter
Your server should now be started and waiting for incoming connections. You can now launch the tracking tutorial.
Running the tracking example
Let us now run the tracker on a video, with the default provided cube model. The video can be found in the data folder of the tutorial and the source code in tutorial-megapose-live-single-object-tracking.cpp located in $VISP_WS/visp/tutorial/tracking/dnn.
The program accepts many arguments, defined here through a vpJsonArgumentParser:
vpJsonArgumentParser parser("Single object tracking with Megapose", "--config", "/");
parser.addArgument("width", width, true, "The image width")
.addArgument("height", height, true, "The image height")
.addArgument("camera", cam, true, "The camera intrinsic parameters. Should correspond to a perspective projection model without distortion.")
.addArgument("detector/scaleFactor", detectorScaleFactor, false, "Pixel intensity rescaling factor. If set to 1/255, then pixel values are between 0 and 1.")
.addArgument("detector/swapRedAndBlue", detectorSwapRB, false, "Whether to swap red and blue channels before feeding the image to the detector.");
Since there are many arguments, we provide a default configuration to run on the video of the cube. This configuration is found in the file $VISP_WS/visp/tutorial/tracking/dnn/data/megapose_cube.json:
{
"height": 480,
"width": 640,
"video-device": "0",
"object": "cube",
"detectionMethod": "click",
"reinitThreshold": 0.5,
"camera": {
"model": "perspectiveWithoutDistortion",
"px": 605.146728515625,
"py": 604.79150390625,
"u0": 325.53253173828125,
"v0": 244.95083618164063
},
"detector": {
"model-path": "/path/to/cube/cube_detector.onnx",
"config": "none",
"type": "yolov7",
"framework": "onnx",
"labels": [
"cube"
],
"mean":{
"red": 0,
"blue": 0,
"green": 0
},
"confidenceThreshold": 0.65,
"nmsThreshold": 0.5,
"filterThreshold": -0.25,
"scaleFactor": 0.003921569,
"swapRedAndBlue": false
},
"megapose": {
"address": "127.0.0.1",
"port": 5555,
"refinerIterations": 1,
"initialisationNumSamples": 576
},
"megaposeObjectToDetectorClass": {
"cube": "cube"
}
}
Among the argument, the most interesting ones are:
width, height: the dimensions of the image.
video-device: The source of the images. Input 0,1,2,... etc for a realtime camera feed, or the name of a video file.
camera: The intrinsics of the camera. Here, the video is captured on an Intel Realsense D435, and the intrinsics are obtained from the realsense SDK. The video is captured by using the tutorial Frame grabbing using Realsense SDK.
reinitThreshold: a threshold between 0 and 1. If the MegaPose's score is below this threshold, it should be reinitialised (requiring a 2D bounding box).
detectionMethod: How to acquire a bounding box of the object in the image.
object: name of the object to track. Should match an object that is in the mesh directory of the MegaPose server.
megapose/address: The IP of the MegaPose server.
megapose/refinerIterations: Number of iterations performed by the refiner model. This impacts both (re)initialization and tracking. Values above 1 may be too slow for tracking.
megapsose/initialisationNumSamples: Number of renders (random poses) used for the initialisation.
For the parameters of the detector (used if detectionMethod == dnn), see Tutorial: Deep learning object detection. Here, the parameters correspond to a YoloV7-tiny, trained only to detect the cube. Note that to train this detector, we acquired ~400 images with Frame grabbing using Realsense SDK, then annotated them with labelImg. A more recent alternative seems to be LabelStudio. The detector should be trained (and exported) with images of the same size as provided to MegaPose.
If the MegaPose server is running on another machine or uses another port, replace the arguments with your values.
If everything goes well, you should obtain results similar to those displayed below:
In this visualization, you can see the 3D model being displayed, as well as the object frame expressed in the camera. The model display can be toggled by pressing T. Displaying can be helpful in two ways:
Visually ensuring that tracking produces coherent results
Verifying that the model is correctly interpreted by megapose
The bar at the bottom displays the score coming from megapose. This score reflects whether the tracking has diverged and a reinitialization is required.
We first create the raw vpMegaPose object, passing as parameters the IP adress and the port, as well as the camera calibration and image resolution. This class can directly be used to perform pose estimation, but we will here prefer the vpMegaPoseTracker class, which provides a simpler interface in the case of tracking. In addition, it allows to call MegaPose asynchronously and we can then use the main thread to perform other operations, such as acquiring and displaying the latest frame.
To the tracker, we provide the name of the object we wish to track, as well as the number of iterations that MegaPose should perform. Run time will scale linearly in the number of iterations.
Once our tracker is initialized, we set the number of samples for coarse pose estimation (when we provide a bounding box detection, but no previous pose estimate).
We also check that the object's name is known to MegaPose. If it is not, then tracking will not be possible.
Finally, we initialize a reference to a future object, which will store the latest pose estimation result.
We can now enter a loop which will start by acquiring the latest image from the camera:
Once we have acquired an image, we continue by checking MegaPose has returned a result. Of course, this will not be the case for the first iteration. If there is indeed a new result, we can check the confidence score to decide if a reinitialization is required and request the rendering from MegaPose to display it afterwards. In addition, we also request a new pose estimation, by setting the callMegapose boolean to true.
if (!callMegapose && trackerFuture.wait_for(std::chrono::milliseconds(0)) == std::future_status::ready) {
if (megaposeEstimate.score < reinitThreshold) { // If confidence is low, require a reinitialisation with 2D detection
initialized = false;
}
}
When requesting a pose estimate, there are two states to handle:
We are not already tracking, or tracking has failed. In this case, we require the 2D bounding box of the object to (re)initialize tracking. To perform detection, we provide two methods
The first, where a trained detection neural network (detectionMethod == "dnn") performs the bounding box regression.
The second, ideal for initial tests, where the user provides the detection. Note that in both cases, the methods (described after) return an optional value: the object may not always be visible in the image.
In the second case, we are already tracking: We can simply feed the latest image to MegaPose as we already have an estimate of the object pose.
* Ask user to provide the detection themselves. They must click to start labelling, then click on the top left and bottom right corner to create the detection.
Optionally (but recommended), an automated way to detect the object. You can for instance train a deep neural network and use it in ViSP, as explained in Tutorial: Deep learning object detection. Since you already have your 3D model, you can use Blender to generate a synthetic dataset and train a detection network without manually annotating images. This process is explained in Tutorial: Generating synthetic data for deep learning with Blenderproc.
This tracking example has been used to illustrate some of MegaPose's properties. First, combining it with a deep learning detection method provides an automatic tracking initialization/reinitialization method.
Second, It is able to track reconstructed meshes and is resistant to occlusions as seen below.
It is also resistant to lighting variations and can track textureless objects.
Finally, MegaPose is an ideal candidate for Pose-Based Visual Servoing. The video below shows an example of a PBVS experiment where MegaPose provides the pose estimation that is given as input to the PBVS control law. See Next steps for more information.
Next steps
To go further, you can look at an example of visual servoing using Megapose, available at servoAfma6MegaposePBVS.cpp
 are known
are known MegaPose can estimate the pose of the object relative to the camera frame
MegaPose can estimate the pose of the object relative to the camera frame 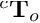 .
.