|
Visual Servoing Platform
version 3.4.0
|
|
Visual Servoing Platform
version 3.4.0
|
This tutorial describes how to use the generic markerless model-based tracker [7], [42] implemented in vpMbGenericTracker with data acquired by a RGB-D camera like the Intel RealSense devices (SR300 or D400 series). You are advised to have read the Tutorial: Markerless generic model-based tracking using a color camera to have an overview of the generic model-based tracker working on images acquired by a color camera that uses moving-edges and keypoints as visual features. We suggest also to follow Tutorial: Markerless generic model-based tracking using a stereo camera to learn how to consider stereo cameras, since a RGB-D camera is in a sense a stereo camera, with the left camera providing the color image and the right the depth image.
Note that all the material (source code, input video, CAD model or XML settings files) described in this tutorial is part of ViSP source code and could be downloaded using the following command:
Considering the use case of a RGB-D camera, the tracker implemented in vpMbGenericTracker class allows to consider a combination of the following visual features:
The moving-edges and KLT features require a RGB camera, more precisely these features operate on grayscale image. The depth normal and dense depth features require a depth map that can be obtained from a RGB-D camera for example.
If you want to use a depth feature, we advise you to choose the dense depth features that is a much more robust method compared to the depth normal feature. Keep also in mind that Kinect-like sensors have a limited depth range (from ~0.8m to ~3.5m).
Note also that combining the visual features can be a good way to improve the tracking robustness (e.g. a stereo tracker with moving edges + keypoints for the left camera and dense depth visual features for the right camera).
The following video demonstrates the use of the generic tracker with a RGB-D sensor using the following features:
In this video, the same setup is used but with:
Depending on your use case the following optional third-parties may be used by the tracker. Make sure ViSP was build with the appropriate 3rd parties:
OpenCV: Essential if you want to use the keypoints as visual features that are detected and tracked thanks to the KLT tracker. This 3rd party may be also useful to consider input videos (mpeg, png, jpeg...).Point Cloud Library: This 3rd party is optional but could be used if your RGB-D sensor provides the depth data as a point cloud. Notice that the source code explained in this tutorial doesn't run if you don't have a version of ViSP build with PCL as 3rd party. Note also that you don't need to install PCL if you don't want to consider depth as visual feature.Ogre 3D: This 3rd party is optional and could be difficult to install on OSX and Windows. To begin with the tracker we don't recommend to install it. Ogre 3D allows to enable Advanced visibility via Ogre3D.Coin 3D: This 3rd party is also optional and difficult to install. That's why we don't recommend to install Coin 3D to begin with the tracker. Coin 3D allows only to consider CAD model in wrml format instead of the home-made CAD model in cao format.It is recommended to install an optimized BLAS library (for instance OpenBLAS) to get better performance with the dense depth feature approach which requires large matrix operations. On Ubuntu Xenial, it is the libopenblas-dev package that should be installed. To select or switch the BLAS library to use, see Handle different versions of BLAS and LAPACK:
You should have something similar to this:
There are 3 choices for the alternative libblas.so.3 (providing /usr/lib/libblas.so.3).
Selection Path Priority Status 0 /usr/lib/openblas-base/libblas.so.3 40 auto mode 1 /usr/lib/atlas-base/atlas/libblas.so.3 35 manual mode 2 /usr/lib/libblas/libblas.so.3 10 manual mode 3 /usr/lib/openblas-base/libblas.so.3 40 manual mode
For classical features working on grayscale image, you have to use the following data type:
You can convert to a grayscale image if the image acquired is in RGBa data type:
For depth features, you need to supply a pointcloud, that means a 2D array where each element contains the X, Y and Z coordinate in the depth sensor frame. The following data type are accepted:
3x1 (X, Y, Z) vector If you have only a depth map, a 2D array where each element (u, v) is the distance Z in meter between the depth sensor frame to the object, you will need to compute the 3D coordinates using the depth sensor intrinsic parameters. We recall that u relates to the array columns, while v relates to the array rows. For instance, without taking into account the distortion (see also vpPixelMeterConversion::convertPoint), the conversion is (u and v are the pixel coordinates, u0, v0, px, py are the intrinsic parameters):
![\[ \left\{\begin{matrix} X = \frac{u - u_0}{px} \times Z \\ Y = \frac{v - v_0}{px} \times Z \end{matrix}\right. \]](form_1413.png)
Here an example of a depth map:
Each tracker is stored in a map, the key corresponding to the name of the camera on which the tracker will process. By default, the camera names are set to:
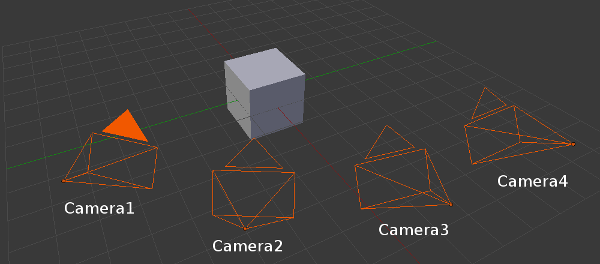
To deal with multiple cameras, in the virtual visual servoing control law we concatenate all the interaction matrices and residual vectors and transform them in a single reference camera frame to compute the reference camera velocity. Thus, we have to know the transformation matrix between each camera and the reference camera.
For example, if the reference camera is "Camera1" ( 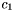 ), we need the following information:
), we need the following information: 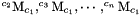 .
.
The following enumeration (vpMbGenericTracker::vpTrackerType) values are available to get the desired model-based tracker:
The tracker declaration is then:
To combine the features:
To "fully exploit" the capabilities of a RGB-D sensor, you can use for instance:
This will declare a tracker with edge + KLT features for the color camera and dense depth feature for the depth sensor.
Each essential method used to initialize the tracker and process the tracking have three signatures in order to ease the call to the method and according to three working modes:
The following table sums up how to call the different methods based on the camera configuration for the main functions.
| Method calling example: | Monocular case | Stereo case | Multiple cameras case | Remarks |
|---|---|---|---|---|
| Construct a model-based edge tracker: | vpMbGenericTracker tracker | vpMbGenericTracker tracker(2, vpMbGenericTracker::EDGE_TRACKER) | vpMbGenericTracker tracker(5, vpMbGenericTracker::EDGE_TRACKER) | The default constructor corresponds to a monocular edge tracker. |
| Load a configuration file: | tracker.loadConfigFile("config.xml") | tracker.loadConfigFile("config1.xml", "config2.xml") | tracker.loadConfigFile(mapOfConfigFiles) | Each tracker can have different parameters (intrinsic parameters, visibility angles, etc.). |
| Load a model file: | tracker.loadModel("model.cao") | tracker.loadModel("model1.cao", "model2.cao") | tracker.loadModel(mapOfModelFiles) | Different models can be used. |
| Get the intrinsic camera parameters: | tracker.getCameraParameters(cam) | tracker.getCameraParameters(cam1, cam2) | tracker.getCameraParameters(mapOfCam) | |
| Set the transformation matrix between each camera and the reference one: | tracker.setCameraTransformationMatrix(mapOfCamTrans) | tracker.setCameraTransformationMatrix(mapOfCamTrans) | For the reference camera, the identity homogeneous matrix must be used. | |
| Setting to display the features: | tracker.setDisplayFeatures(true) | tracker.setDisplayFeatures(true) | tracker.setDisplayFeatures(true) | This is a general parameter. |
| Initialize the pose by click: | tracker.initClick(I, "f_init.init") | tracker.initClick(I1, I2, "f_init1.init", "f_init2.init") | tracker.initClick(mapOfImg, mapOfInitFiles) | Assuming the transformation matrices between the cameras have been set, some init files can be omitted as long as the reference camera has an init file. The corresponding images must be supplied. |
| Track the object: | tracker.track(I) | tracker.track(I1, I2) | tracker.track(mapOfImg) | See the documentation to track with pointcloud. |
| Get the pose: | tracker.getPose(cMo) | tracker.getPose(c1Mo, c2Mo) | tracker.getPose(mapOfPoses) | tracker.getPose(cMo) will return the pose for the reference camera in the stereo/multiple cameras configurations. |
| Display the model: | tracker.display(I, cMo, cam, ...) | tracker.display(I1, I2, c1Mo, c2Mo, cam1, cam2, ...) | tracker.display(mapOfImg, mapOfPoses, mapOfCam, ...) |
We provide hereafter an example implemented in tutorial-mb-generic-tracker-rgbd.cpp that shows how to track a cube modeled in cao format using moving-eges, keypoints and dense depth as visual features. The input data (color image, depth map and point clould) were acquired by a RealSense RGB-D camera.
Once built, run the binary:
After initialization by 4 user clicks, the tracker is running and produces the following output:

The source code that is very similar to the one provided in Tutorial: Markerless generic model-based tracking using a stereo camera is the following:
The previous source code shows how to use the vpMbGenericTracker class using depth as visual feature. The procedure to configure the tracker remains the same:
cube.xml) for the color camera and for the depth camera (cube_depth.xml). These files contain the camera intrinsic parameters associated to each sensordepth_M_color.txt) between the depth sensor and the color cameracube.init file used to initialize the tracker by a user interaction that consists in clicking on 4 cube cornerscube.cao)Please refer to the tutorial Tutorial: Markerless generic model-based tracking using a color camera in order to have explanations about the configuration parameters (Tracker settings) and how to model an object in a ViSP compatible format (CAD model in cao format).
To use vpMbGenericTracker we include first the corresponding header:
Then we implemented the function read_data() to read the color images color_image_%04d.jpg, the depth map depth_image_%04d.bin and the point cloud point_cloud_%04d.bin.
We need grayscale images for the tracking, one corresponding to the color image, the other for the depth image:
We need also a point cloud container that will be updated from the depth map
To set the type of the tracker (the first parameter is the number of cameras, the second parameter is the type of the tracker(s)):
To load the configuration file, we use:
To load the 3D object model, we use:
We can also use the following setting that enables the display of the features used during the tracking:
We then set the map of transformations between our two sensors indicating that the color sensor frame is the reference frame. depth_M_color matrix is read from the input file depth_M_color.txt.
We set also the map of images
The initial pose is set by clicking on specific points in the image after setting a map of *.init files (in our case cube.init:
The tracking is done by:
To get the current camera pose:
To display the model with the estimated pose and also the object frame:
Hereafter we provide the information to test the tracker with different objects (cube, teabox, lego-square) with an Intel Realsense D435 or SR300 camera.
Enter model-based tracker tutorial build folder:
There is tutorial-mb-generic-tracker-rgbd-realsense binary that corresponds to the build of tutorial-mb-generic-tracker-rgbd-realsense.cpp example. This example is an extension of tutorial-mb-generic-tracker-rgbd.cpp that was explained in Getting started section.
To see the command line options that are available run:
model/cube/cube.cao file replacing 0.042 with the appropriate value expressed in meters.To track a 4.2 cm cube with manual initialization, run:
You should obtain similar results:
Now if the tracker is working, you can learn the object adding --learn command line option:
Once initialized by 4 user clicks, use the left click to learn on one or two images and then the right click to quit. In the terminal you should see printings like:
You can now use this learning to automize tracker initialization with --auto_init option:
model/cube/cube.cao with the appropriate size values expressed in meters.To track the 16.5 x 6.8 x 8 cm teabox with manual initialization, run:
You should obtain similar results:
Now if the tracker is working, you can learn the object adding --learn command line option:
Once initialized by 4 user clicks, use the left click to learn on one or two images and then the right click to quit. In the terminal you should see printings like:
You can now use this learning to automize tracker initialization with --auto_init option:
Here we consider an object made with four 2x4 lego bricks assembled as a square. To track this object with manual initialization, run:
You should obtain similar results:
Now if the tracker is working, you can learn the object adding --learn command line option:
Once initialized by 4 user clicks, use the left click to learn on one or two images and then the right click to quit. In the terminal you should see printings like:
You can now use this learning to automize tracker initialization with --auto_init option:
If you have an Intel Realsense device, you are now ready to experiment the generic model-based tracker on a cube that has an AprilTag on one face following Tutorial: Markerless generic model-based tracking using AprilTag for initialization (use case).
You can also follow Tutorial: Markerless model-based tracker CAD model editor - GSoC 2017 project.
 1.8.11
1.8.11 
