This tutorial will show you how to use keypoints to detect and estimate the pose of a known object using his cad model. The first step consists in detecting and learning keypoints located on the faces of an object, while the second step makes the matching between the detected keypoints in the query image with those previously learned. The pair of matches are then used to estimate the pose of the object with the knowledge of the correspondences between the 2D and 3D coordinates.
The next section presents a basic example of the detection of a teabox with a detailed description of the different steps.
Note that all the material (source code and video) described in this tutorial is part of ViSP source code and could be downloaded using the following command:
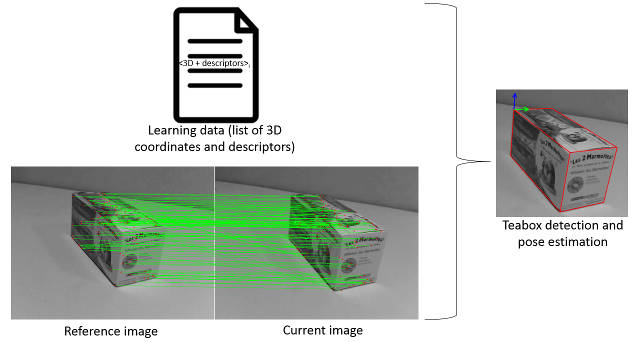
A quick overview of the principle is summed-up in the following diagrams.
Learning step.
The first part of the process consists in learning the characteristics of the considered object by extracting the keypoints detected on the different faces. We use here the model-based tracker initialized given a known initial pose to have access to the cad model of the object. The cad model is then used to select only keypoints on faces that are visible and to calculate the 3D coordinates of keypoints.
Note
The calculation of the 3D coordinates of a keypoint is based on a planar location hypothesis. We assume that the keypoint is located on a planar face and the Z-coordinate is retrieved according to the proportional relation between the plane equation expressed in the normalized camera frame (derived from the image coordinate) and the same plane equation expressed in the camera frame, thanks to the known pose of the object.
In this example the learned data (the list of 3D coordinates and the corresponding descriptors) are saved in a file and will be used later in the detection part.
Detection step.
In a query image where we want to detect the object, we find the matches between the keypoints detected in the current image with those previously learned. The estimation of the pose of the object can then be computed with the 3D/2D information.
The next section presents an example of the detection and the pose estimation of a teabox.
Teabox detection and pose estimation
The following video shows the resulting detection and localization of a teabox that is learned on the first image of the video.
The corresponding code is available in tutorial-detection-object-mbt-deprecated.cpp. It contains the different steps to learn the teabox object on one image (the first image of the video) and then detect and get the pose of the teabox in the rest of the video.
std::cout << "Catch an exception: " << e << std::endl;
}
#else
(void)argc;
(void)argv;
std::cout << "Install OpenCV and rebuild ViSP to use this example." << std::endl;
#endif
return 0;
}
You may recognize with the following lines the code used in tutorial-mb-edge-tracker.cpp to initialize the model-based tracker at a given pose and with the appropriate configuration.
The modifications made to the code start from now.
First, we have to choose about which type of keypoints will be used. SIFT keypoints are a widely type of keypoints used in computer vision, but depending of your version of OpenCV and due to some patents, certain types of keypoints will not be available. Here, we will use SIFT if available, otherwise a combination of FAST keypoint detector and ORB descriptor extractor.
If libxml2 is available, you can load the configuration (type of detector, extractor, matcher, ransac pose estimation parameters) directly with an xml configuration file :
But we need to keep keypoints only on faces of the teabox. This is done by using the model-based tracker to first eliminate keypoints which do not belong to the teabox and secondly to have the plane equation for each faces (and so to be able to compute the 3D coordinate from the 2D information).
The next step is the building of the reference keypoints. The descriptors for each keypoints are also extracted and the reference data consist of the lists of keypoints / descriptors and the list of 3D points.
We save the learning data in a binary format (the other possibilitie is to save in an xml format but which takes more space) to be able to use it later.
We declare now another instance of the vpKeyPoint class dedicated this time to the detection of the teabox. If libxml2 is available, the configuration is directly loaded from an xml file, otherwise this is done directly in the code.
We are now ready to detect the teabox in a query image. The call to the function vpKeyPoint::matchPoint() returns true if the matching was successful and permits to get the estimated homogeneous matrix corresponding to the pose of the object. The reprojection error is also computed.
if (keypoint_detection.matchPoint(I, cam, cMo, error, elapsedTime)) {
In order to display the result, we use the tracker initialized at the estimated pose and we display also the location of the world frame:
In this configuration file, SIFT keypoints are used.
Let us explain now the configuration of the matcher:
a brute force matching will explore all the possible solutions to match a considered keypoints detected in the current image to the closest (in descriptor distance term) one in the reference set, contrary to the other type of matching using the library FLANN (Fast Library for Approximate Nearest Neighbors) which contains some optimizations to reduce the complexity of the solution set,
to eliminate some possible false matching, one technique consists of keeping only the keypoints whose are sufficienly discriminated using a ratio test.
Now, for the Ransac pose estimation part :
two methods are provided to estimate the pose in a robust way: one using OpenCV, the other method uses a virtual visual servoing approach using ViSP,
basically, a Ransac method is composed of two steps repeated a certain number of iterations: first we pick randomly 4 points and estimate the pose, the second step is to keep all points which sufficienly "agree" (the reprojection error is below a threshold) with the pose determinated in the first step. These points are inliers and form the consensus set, the other are outliers. If enough points are in the consensus set (here 20 % of all the points), the pose is refined and returned, otherwise another iteration is made (here 200 iterations maximum).
Below you will also find the content of detection-lconfig.xml configuration file, also provided in this example. It allows to use FAST detector and ORB extractor.
The following video shows an extension of the previous example where here we learn a cube from 3 images and then detect an localize the cube in all the images of the video.
The vpKeyPoint::buildReference() allows to append the current detected keypoints with those already present by setting the function parameter append to true.
But before that, the same learning procedure must be done in order to train on multiple images. We detect keypoints on the desired image:
How to display the matching when the learning is done on multiple images
In this section we will explain how to display the matching between keypoints detected in the current image and their correspondances in the reference images that are used during the learning stage, as given in the next video:
Warning
If you want to load the learning data from a file, you have to use a learning file that contains training images (with the parameter saveTrainingImages vpKeyPoint::saveLearningData() set to true when saving the file, by default it is).
Before showing how to display the matching for all the training images, we have to attribute an unique identifier (a positive integer) for the set of keypoints learned for a particular image during the training process:
Finally, we can also display the model in the matching image. For that, we have to modify the principal point offset of the intrinsic parameter. This is more or less an hack as you have to manually change the principal point coordinate to make it works.
You can refer to the full code in the section How to learn keypoints from multiple images to have an example of how to learn from multiple images and how to display all the matching.

 1.8.11
1.8.11 
