|
Visual Servoing Platform
version 3.6.1 under development (2025-02-27)
|
|
Visual Servoing Platform
version 3.6.1 under development (2025-02-27)
|
This tutorial focuses on basic linear algebra operations such as vector and matrix multiplication.
In ViSP, such basic operations are mainly implemented in vpMatrix class and are using BLAS/LAPACK dgemm (double general matrix multiplication) and dgemv (double general matrix vector multiplication) functions in order to:
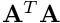 or
or  using either:
using either:
These optimized operations are based on the use of BLAS and LAPACK third-party libraries. Several optimized third-party implementations are available for BLAS/LAPACK, but only one of the following third-party is used at the same time:
oneMKL is included by selecting "Operating System: Linux", "Distribution: Web & Local" and "Installer Type: Local". At the time this tutorial was written we downloaded l_BaseKit_p_2021.1.0.2659_offline.sh.sudo. $ sudo sh l_BaseKit_p_2021.1.0.2659_offline.sh
/opt/intel/oneapisetvars.sh script in bashrc file running: $ echo "source /opt/intel/oneapi/setvars.sh" >> ~/.bashrc $ source ~/.bashrc $ env | grep MKL MKLROOT=/opt/intel/oneapi/mkl/latest
$ sudo apt install libopenblas-dev
$ brew install openblas
$ sudo apt install libatlas-base-dev
$ sudo apt install libgsl-dev
$ brew install gsl
$ sudo apt install liblapack-dev libblas-dev
If none of these third-parties is installed, ViSP provides a build-in version of Lapack that is not optimized and that could be used instead. Note that depending on our test performances some linear algebra operations may use lapack built-in or naive code when we found that it runs faster.
MKL, OpenBLAS, Atlas, GSL or Netlib is installed VISP_HAVE_LAPACK macro is defined in vpConfig.h file. There is also a more specific macro that is defined with the used 3rd party as suffix, VISP_HAVE_LAPACK_MKL, VISP_HAVE_LAPACK_OPENBLAS, VISP_HAVE_LAPACK_ATLAS, VISP_HAVE_LAPACK_GSL and VISP_HAVE_LAPACK_NETLIB respectively.VISP_HAVE_LAPACK and VISP_HAVE_LAPACK_BUILT_IN macro are then defined.$ cd $VISP_WS/visp-build $ ccmake ../vispAt this step, selection is achieved tuning the following line:
USE_BLAS/LAPACK [ MKL | OpenBLAS | Atlas | GSL | Netlib ]
Note also that if you select OpenBLAS, or Atlas, or Netlib there is the possibility to change the used third-party during run time, without re-building ViSP. On Ubuntu, this could be achieved using update-alternatives:
Selecting LAPACK implementation:
$ sudo update-alternatives --config liblapack.so.3-x86_64-linux-gnu There are 3 choices for the alternative liblapack.so.3-x86_64-linux-gnu (providing /usr/lib/x86_64-linux-gnu/liblapack.so.3). Selection Path Priority Status ------------------------------------------------------------ 0 /usr/lib/x86_64-linux-gnu/openblas/liblapack.so.3 40 auto mode * 1 /usr/lib/x86_64-linux-gnu/atlas/liblapack.so.3 35 manual mode 2 /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3 10 manual mode 3 /usr/lib/x86_64-linux-gnu/openblas/liblapack.so.3 40 manual mode
and selecting BLAS implementation:
$ sudo update-alternatives --config libblas.so.3-x86_64-linux-gnu There are 3 choices for the alternative libblas.so.3-x86_64-linux-gnu (providing /usr/lib/x86_64-linux-gnu/libblas.so.3). Selection Path Priority Status ------------------------------------------------------------ 0 /usr/lib/x86_64-linux-gnu/openblas/libblas.so.3 40 auto mode * 1 /usr/lib/x86_64-linux-gnu/atlas/libblas.so.3 35 manual mode 2 /usr/lib/x86_64-linux-gnu/blas/libblas.so.3 10 manual mode 3 /usr/lib/x86_64-linux-gnu/openblas/libblas.so.3 40 manual mode
In the previous example BLAS and LAPACK are selected from Atlas implementation.
MKL and select USE_BLAS/LAPACK MKLor if you installed
GSL and select USE_BLAS/LAPACK GSLthere is no possibility to switch to
OpenBLAS, or Atlas or Netlib during run time. You need to modify USE_BLAS/LAPACK cmake option and build again ViSP.Since performance depends on the OS and the size of the matrices or vectors that you manipulate, there is not a clear answer to this question, but from our experience we recommend to use MKL that seems usually faster than OpenBLAS, Atlas, GSL and Netlib at least on a 8 cores laptop running Ubuntu 18.04.
We also experienced that using MKL, OpenBLAS, Atlas, GSL or Netlib dgemm and dgemv functionalities on small matrices or vectors is not always a good option since using them bring an additional processing cost. That's why since ViSP 3.3.1 we introduce vpMatrix::setLapackMatrixMinSize() function that allows the user to specify the minimum vector size or the minimum matrix rows or columns size from which Lapack dgemm and dgemv are used. Default min size is set to 0 (meaning that Lapack is always used). This min size could be retrieved using vpMatrix::getLapackMatrixMinSize().
To help the user to select the appropriate third-party between MKL, OpenBLAS, Atlas, GSL and Netlib with regard to the use-case, there is a benchmark that could be useful. It compares the performances between a naive implementation and an optimized version of basic linear operations.
$ cd $VISP_WS/visp-build/modules/core $ make -j4 $ ./perfMatrixMultiplication --benchmark --lapack-min-size 8
This binary produces the following output for matrix-matrix multiplication:
Default matrix/vector min size to enable Blas/Lapack optimization: 8
Used matrix/vector min size to enable Blas/Lapack optimization: 8
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
perfMatrixMultiplication is a Catch v2.9.2 host application.
Run with -? for options
-------------------------------------------------------------------------------
Benchmark matrix-matrix multiplication
...............................................................................
benchmark name samples iterations estimated
mean low mean high mean
std dev low std dev high std dev
-------------------------------------------------------------------------------
(3x3)x(3x3) - Naive code 100 237 2.0382 ms
88 ns 87 ns 93 ns
13 ns 1 ns 24 ns
(3x3)x(3x3) - ViSP 100 213 2.0448 ms
88 ns 88 ns 89 ns
1 ns 0 ns 3 ns
(6x6)x(6x6) - Naive code 100 95 2.0615 ms
210 ns 210 ns 212 ns
3 ns 0 ns 7 ns
(6x6)x(6x6) - ViSP 100 93 2.0646 ms
222 ns 221 ns 224 ns
4 ns 0 ns 9 ns
(8x8)x(8x8) - Naive code 100 54 2.0682 ms
380 ns 379 ns 381 ns
3 ns 0 ns 8 ns
(8x8)x(8x8) - ViSP 100 48 2.0736 ms
432 ns 431 ns 435 ns
6 ns 0 ns 15 ns
(10x10)x(10x10) - Naive code 100 31 2.0925 ms
709 ns 682 ns 767 ns
194 ns 103 ns 322 ns
(10x10)x(10x10) - ViSP 100 46 2.0608 ms
447 ns 444 ns 462 ns
30 ns 0 ns 73 ns
(20x20)x(20x20) - Naive code 100 4 2.1844 ms
5.426 us 5.418 us 5.445 us
54 ns 6 ns 109 ns
(20x20)x(20x20) - ViSP 100 18 2.1474 ms
1.189 us 1.172 us 1.268 us
159 ns 11 ns 379 ns
(6x200)x(200x6) - Naive code 100 3 2.2248 ms
7.206 us 7.194 us 7.239 us
90 ns 5 ns 179 ns
(6x200)x(200x6) - ViSP 100 3 2.1648 ms
7.343 us 7.266 us 7.467 us
490 ns 332 ns 679 ns
As stated in the introduction, if you install OpenBLAS, Atlas and Netlib don't forget that with Ubuntu you can select which of these third-party is used during run time using update-alternatives --config liblapack.so.3-x86_64-linux-gnu, meaning that there is no need to run CMake and build ViSP again. Configuring with CMake and building ViSP is only mandatory if you want to change from MKL to one of OpenBLAS, Atlas or Netlib third-party, and vice-versa.
There is also the possibility to run the benchmark modifying the minimum size of matrices and vector requested to enable Blas/Lapack usage in order to see the effect on your platform and tune this parameter. For example to use always Blas/Lapack even for small matrices you can set minimum size to 0:
./perfMatrixMultiplication --benchmark --lapack-min-size 0
Now the binary produces the following output for matrix-matrix multiplication:
$ ./perfMatrixMultiplication --benchmark --lapack-min-size 0
Default matrix/vector min size to enable Blas/Lapack optimization: 8
Used matrix/vector min size to enable Blas/Lapack optimization: 0
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
perfMatrixMultiplication is a Catch v2.9.2 host application.
Run with -? for options
-------------------------------------------------------------------------------
Benchmark matrix-matrix multiplication
...............................................................................
benchmark name samples iterations estimated
mean low mean high mean
std dev low std dev high std dev
-------------------------------------------------------------------------------
(3x3)x(3x3) - Naive code 100 231 2.0097 ms
92 ns 87 ns 106 ns
39 ns 17 ns 81 ns
(3x3)x(3x3) - ViSP 100 84 2.0328 ms
233 ns 232 ns 237 ns
7 ns 0 ns 18 ns
(6x6)x(6x6) - Naive code 100 95 2.033 ms
209 ns 208 ns 210 ns
2 ns 0 ns 5 ns
(6x6)x(6x6) - ViSP 100 70 2.03 ms
293 ns 292 ns 301 ns
16 ns 0 ns 38 ns
(8x8)x(8x8) - Naive code 100 53 2.0405 ms
379 ns 379 ns 381 ns
4 ns 0 ns 9 ns
(8x8)x(8x8) - ViSP 100 61 2.0313 ms
333 ns 330 ns 342 ns
19 ns 2 ns 47 ns
(10x10)x(10x10) - Naive code 100 30 2.055 ms
667 ns 665 ns 671 ns
9 ns 1 ns 20 ns
(10x10)x(10x10) - ViSP 100 46 2.0654 ms
490 ns 461 ns 542 ns
194 ns 122 ns 278 ns
(20x20)x(20x20) - Naive code 100 4 2.5972 ms
6.441 us 6.434 us 6.466 us
60 ns 8 ns 141 ns
(20x20)x(20x20) - ViSP 100 18 2.133 ms
1.179 us 1.163 us 1.253 us
149 ns 9 ns 355 ns
(6x200)x(200x6) - Naive code 100 3 2.1447 ms
7.172 us 7.159 us 7.206 us
94 ns 5 ns 189 ns
(6x200)x(200x6) - ViSP 100 12 2.2092 ms
1.852 us 1.839 us 1.901 us
120 ns 2 ns 287 ns
The following table gives some results obtained on Ubuntu 18.04 with a DELL Laptop equipped with an Intel® Core™ i7-8650U CPU @ 1.90GHz × 8 and 32 GB RAM. Results were obtained using Intel MKL version 2020.0.166. Other 3rd parties were installed from ubuntu packages. Performance execution time was obtained using:
$ ./perfMatrixMultiplication --benchmark --lapack-min-size 0
that was build setting the appropriate USE_BLAS/LAPACK=[ MKL | OpenBLAS | Atlas | GSL | Netlib ] CMake option during configuration.
Moreover, when OpenBLAS, Atlas or Netlib were selected we used update-alternatives tool to selected the corresponding BLAS / LAPACK library using:
$ sudo update-alternatives --config liblapack.so.3-x86_64-linux-gnu $ sudo update-alternatives --config libblas.so.3-x86_64-linux-gnu
Next table summarises the results we obtained:
| Operation Type | Operation Size | MKL | OpenBLAS | Atlas | GSL | Netlib | build-in | Without Lapack |
|---|---|---|---|---|---|---|---|---|
| Multiplication | [6x6] * [6x6] | 179 ns | 359 ns | 309 ns | 286 ns | 280 ns | 265 ns | 261 ns |
| [6x200] * [200x6] | 615 ns | 2.034 us | 2.68 us | 7.203 us | 3.629 us | 7.181 us | 7.182 us | |
| [200x6] * [6x200] | 29.848 us | 43.024 us | 71.391 us | 151.461 us | 127.576 us | 145.931 us | 146.265 us | |
| [6x6] * [6x1] | 123 ns | 213 ns | 164 ns | 157 ns | 197 ns | 153 ns | 155 ns | |
| [6x200] * [200x1] | 201 ns | 322 ns | 743 ns | 926 ns | 1.269 us | 856 ns | 895 ns | |
| [200x6] * [6x1] | 781 ns | 973 ns | 806 ns | 1.237 us | 1.413 us | 1.179 us | 1.187 us | |
| A^T * A | [6x6] | 223 ns | 374 ns | 403 ns | 218 ns | 279 ns | 160 ns | 222 ns |
| [6x200] | 25.388 us | 43.2 us | 62.494 us | 96.792 us | 125.529 us | 96.423 us | 96.96 us | |
| [200x6] | 690 ns | 2.158 us | 3.701 us | 4.231 us | 2.126 us | 4.23 us | 4.226 us | |
| A * A^T | [6x6] | 267 ns | 397 ns | 401 ns | 217 ns | 323 ns | 209 ns | 209 ns |
| [6x200] | 947 ns | 2.041 us | 3.187 us | 4.058 us | 7.072 us | 4.162 us | 4.074 us | |
| [200x6] | 26.514 us | 45.225 us | 62.473 us | 91.459 us | 148.771 us | 134.956 us | 78.884 us |
The previous table shows the following trend:
The following table compares execution time obtained running ./modules/mbt/testGenericTracker -d -D:
| sample step | MKL | OpenBLAS | Atlas | GSL | Netlib | built-in |
|---|---|---|---|---|---|---|
| me = 5 depth = 1 | 31.0628 ms | 60.5757 ms | 43.9102 ms | 42.2287 ms | 46.9188 ms | 43.299 ms |
Here also, better results are obtained with MKL.
The next table compares execution time obtained running ./example/direct-visual-servoing/photometricVisualServoingWithoutVpServo -c -d:
| MKL | OpenBLAS | Atlas | GSL | Netlib | built-in |
|---|---|---|---|---|---|
| 2388.54 | 2421.17 ms | 2609.84 ms | 2742.55 ms | 2850.84 ms | 2736.48 ms |
Here MKL and OpenBLAS bring similar performances.
You are now ready to to continue with tutorials dedicated to Image manipulation.